2023年新疆“天山固网杯”网络安全技能竞赛|Misc Writeup
网抑云
打开文档的时候发现有错误。后缀改为zip,打开发现有一个字符串come666,在content_types.xml中发现存在图片的base64编码。接下来就是分析图片,因为之前拿到了keycome666,猜测图片为silenteye加密,解密后得到flag.txt。
xicag-cegug-fehyg-kyvyf-fonok-dutif-lusyf-bonuf-hunif-nysif-lisif-fonef-kosik-kotif-bonak-dytuk-fomaf-bamyk-gevef-hevyl-texax
再根据字符串特征,字符串bubblebabble解密里得到flag。
DASCTF{3db7700f5e90713e60f50eb4ca0bd959}
这就是b@se而已
base64表缺失了四个字符,爆破一下就可以,然后换表base64解密。
爆破出来的表是:
YOJyHo57WlUFzCfDgjn0Sb9ET6ei/sqVLX42kNaIhr+dtPm1u3AMKpwRGvcxQZ8B
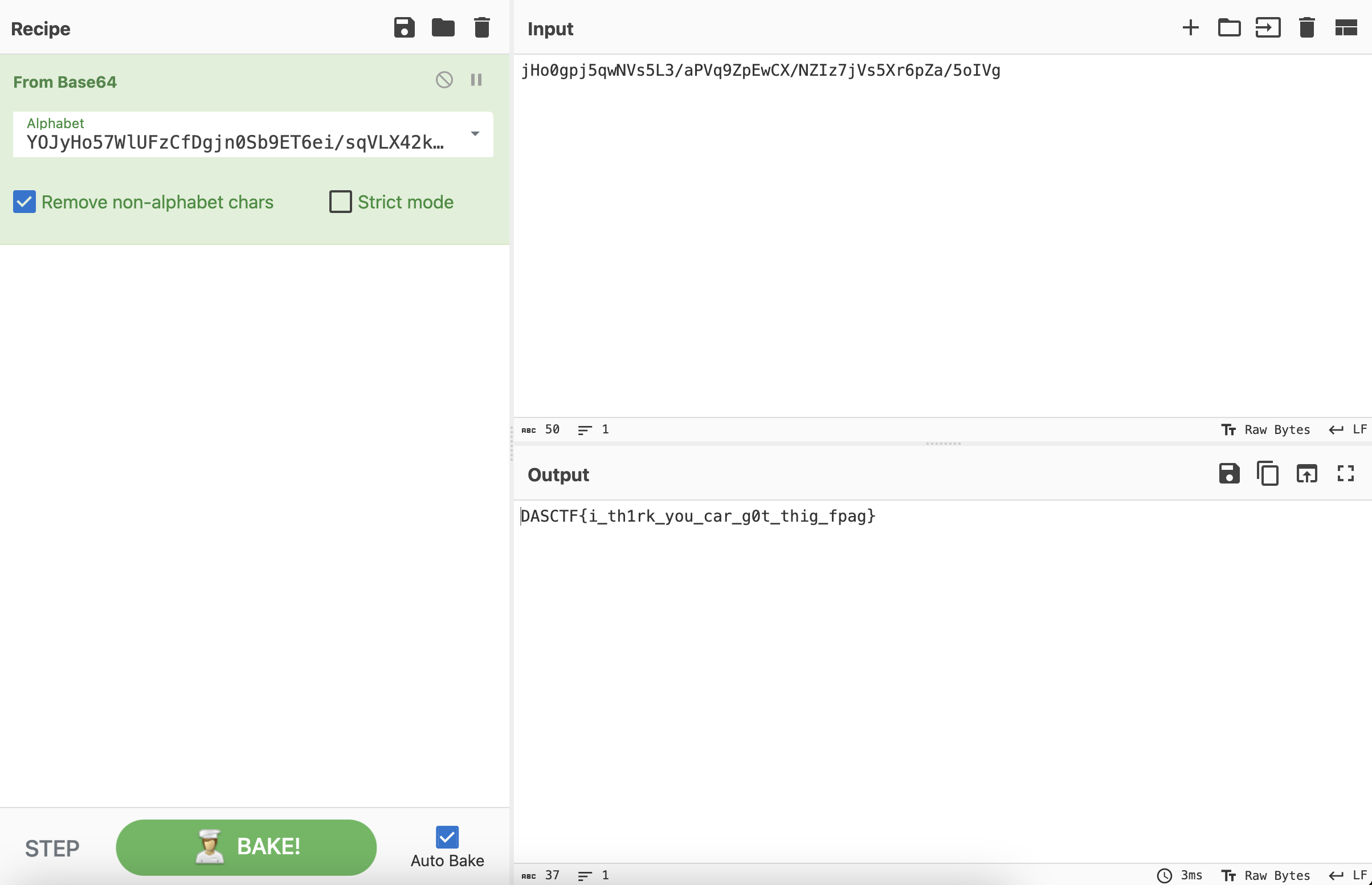
最终得到的flag为:
DASCTF{i_th1rk_you_car_g0t_thig_fpag}
keyboard
键盘流量解密,删掉的是key,敲出来的内容是密文。
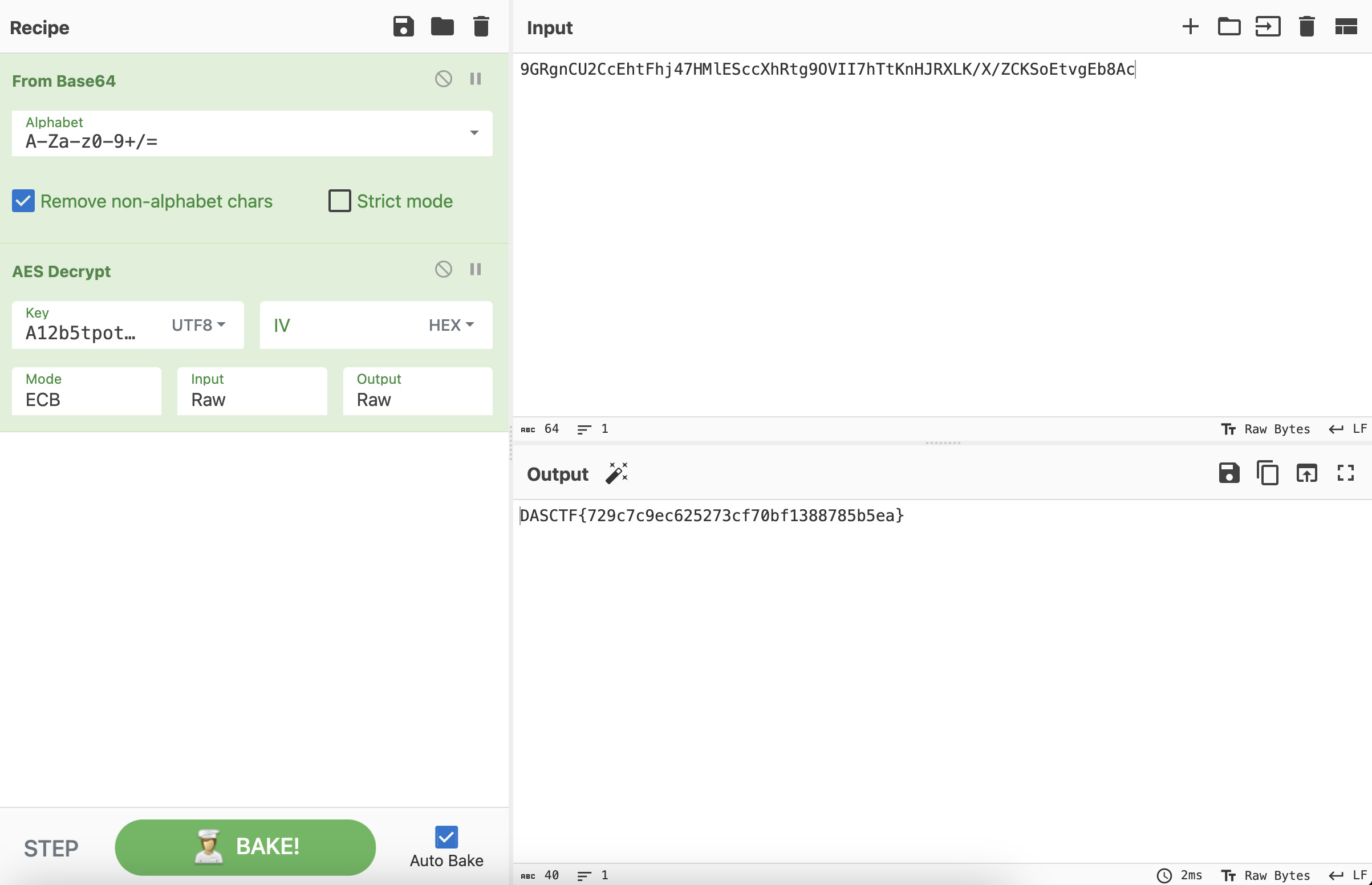
NTLMShark01
使用Wireshark从SMB流量中提取所有传输的文件。
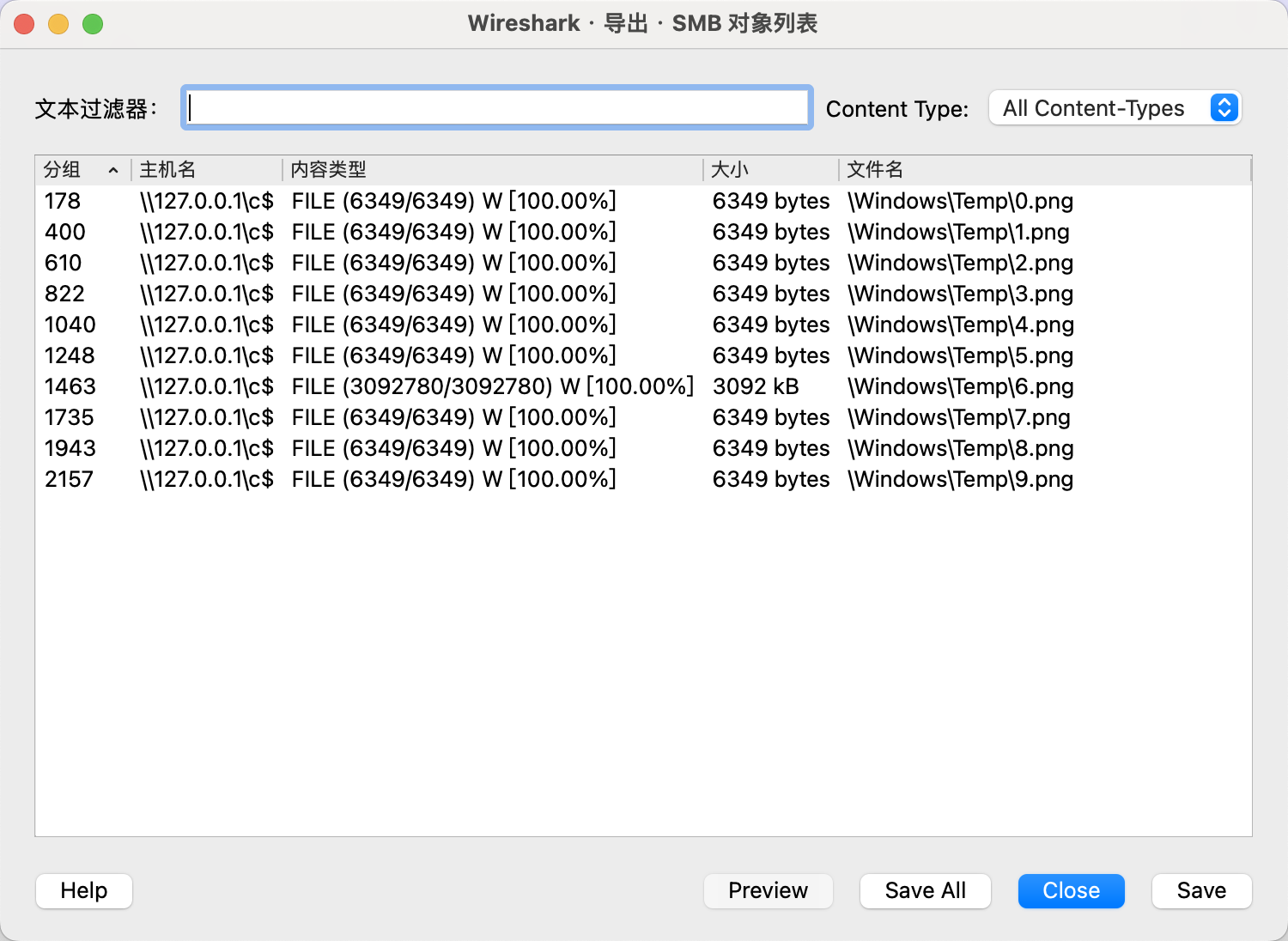
第6张图片是有问题的,查看一下十六进制发现是7z压缩包,打开是一个passwords的字典。猜测是等会爆破要用的。
继续分析流量,ntlmssp过滤一下流量。具体为什么这么做,可以了解一下NTLMv2的原理,三好学生师傅的博客已经讲的很清楚了。
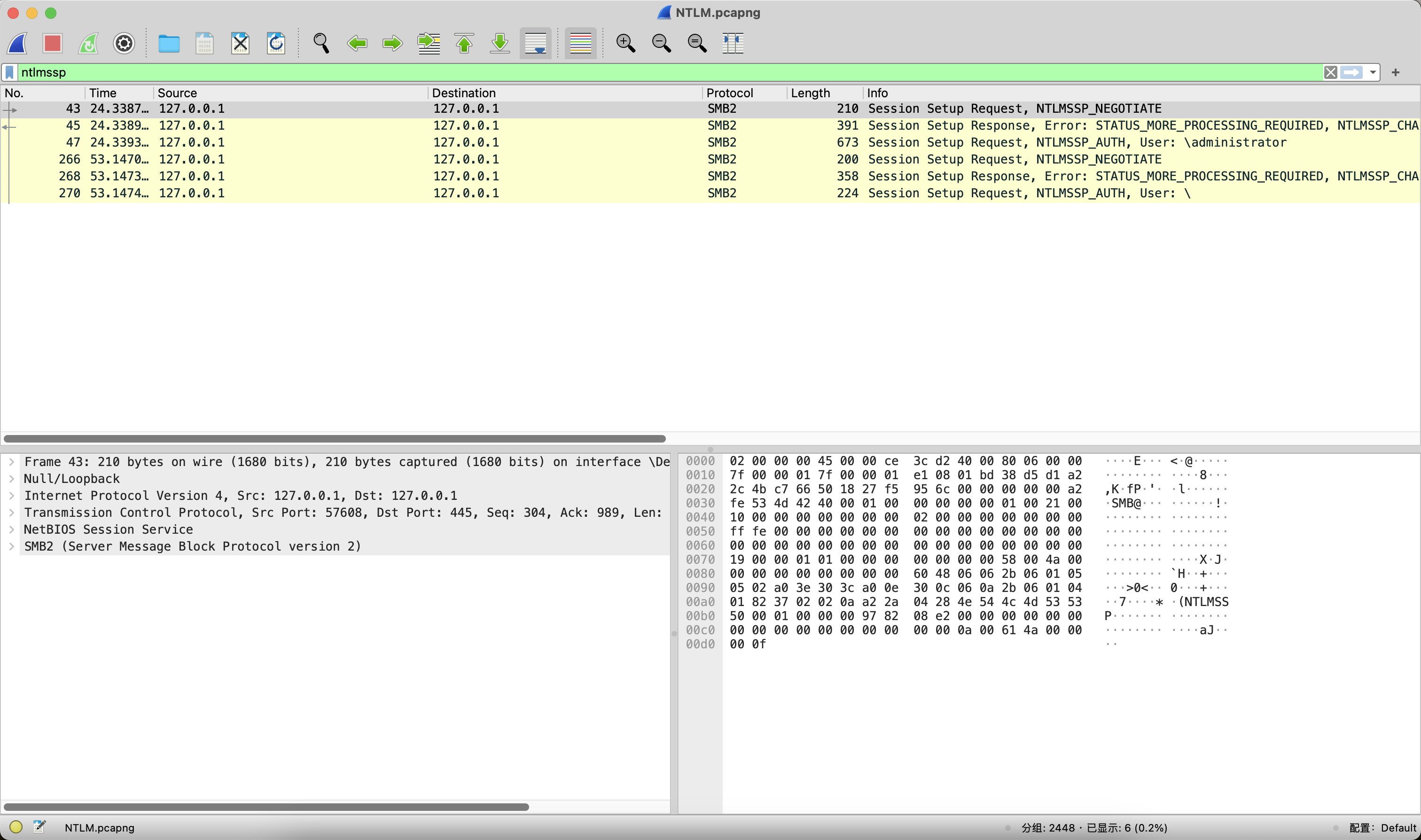
因为题目要求提交管理员的密码,所以需要从NTLM流中找到数据来解密。可以用NTLMRawUnhide这个脚本一键提取出数据。
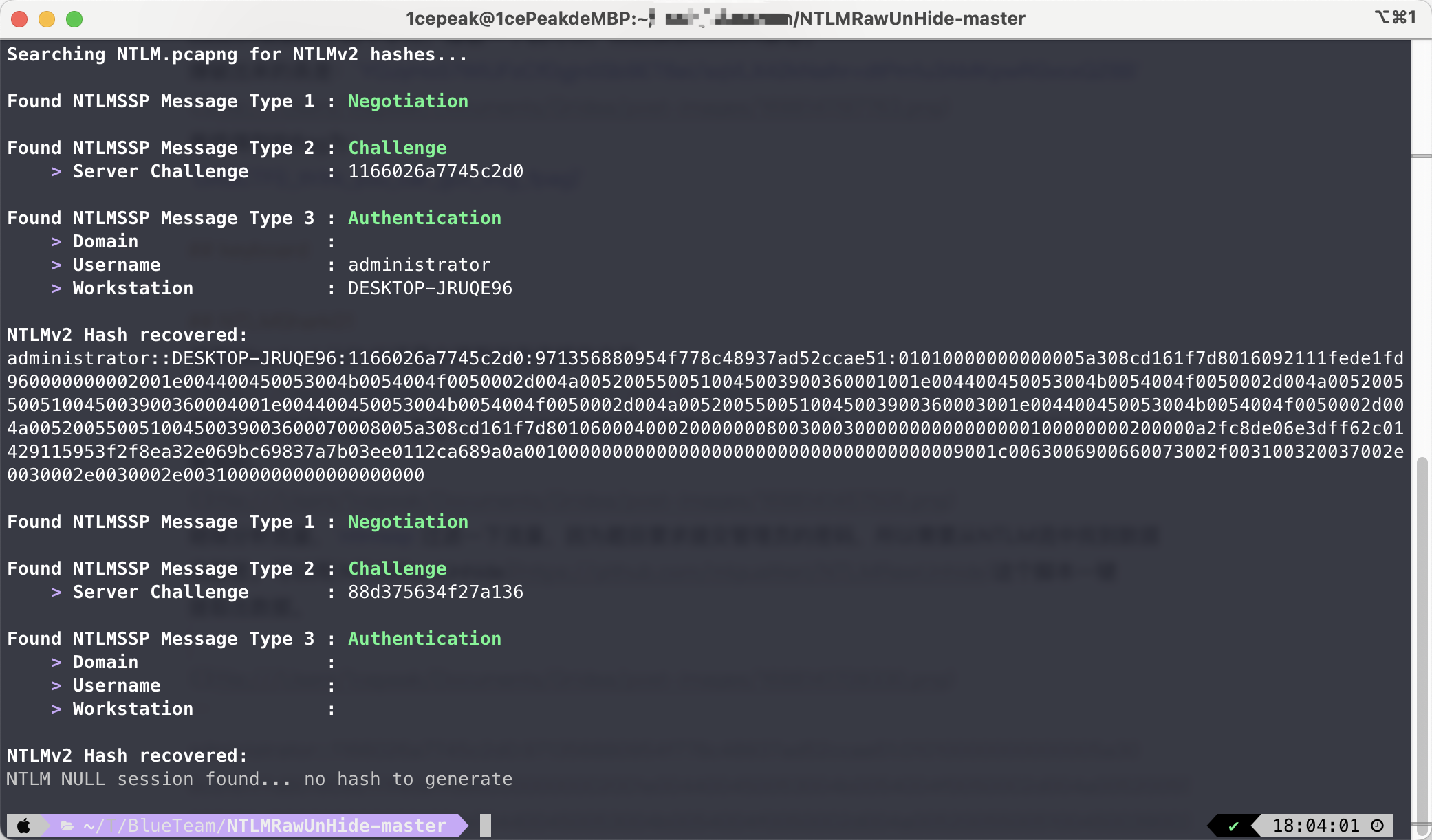
administrator:::1166026a7745c2d0:971356880954f778c48937ad52ccae51:01010000000000005a308cd161f7d8016092111fede1fd960000000002001e004400450053004b0054004f0050002d004a0052005500510045003900360001001e004400450053004b0054004f0050002d004a0052005500510045003900360004001e004400450053004b0054004f0050002d004a0052005500510045003900360003001e004400450053004b0054004f0050002d004a00520055005100450039003600070008005a308cd161f7d80106000400020000000800300030000000000000000100000000200000a2fc8de06e3dff62c01429115953f2f8ea32e069bc69837a7b03ee0112ca689a0a0010000000000000000000000000000000000009001c0063006900660073002f003100320037002e0030002e0030002e0031000000000000000000
接下来就是用之前提取出来的字典爆破了。

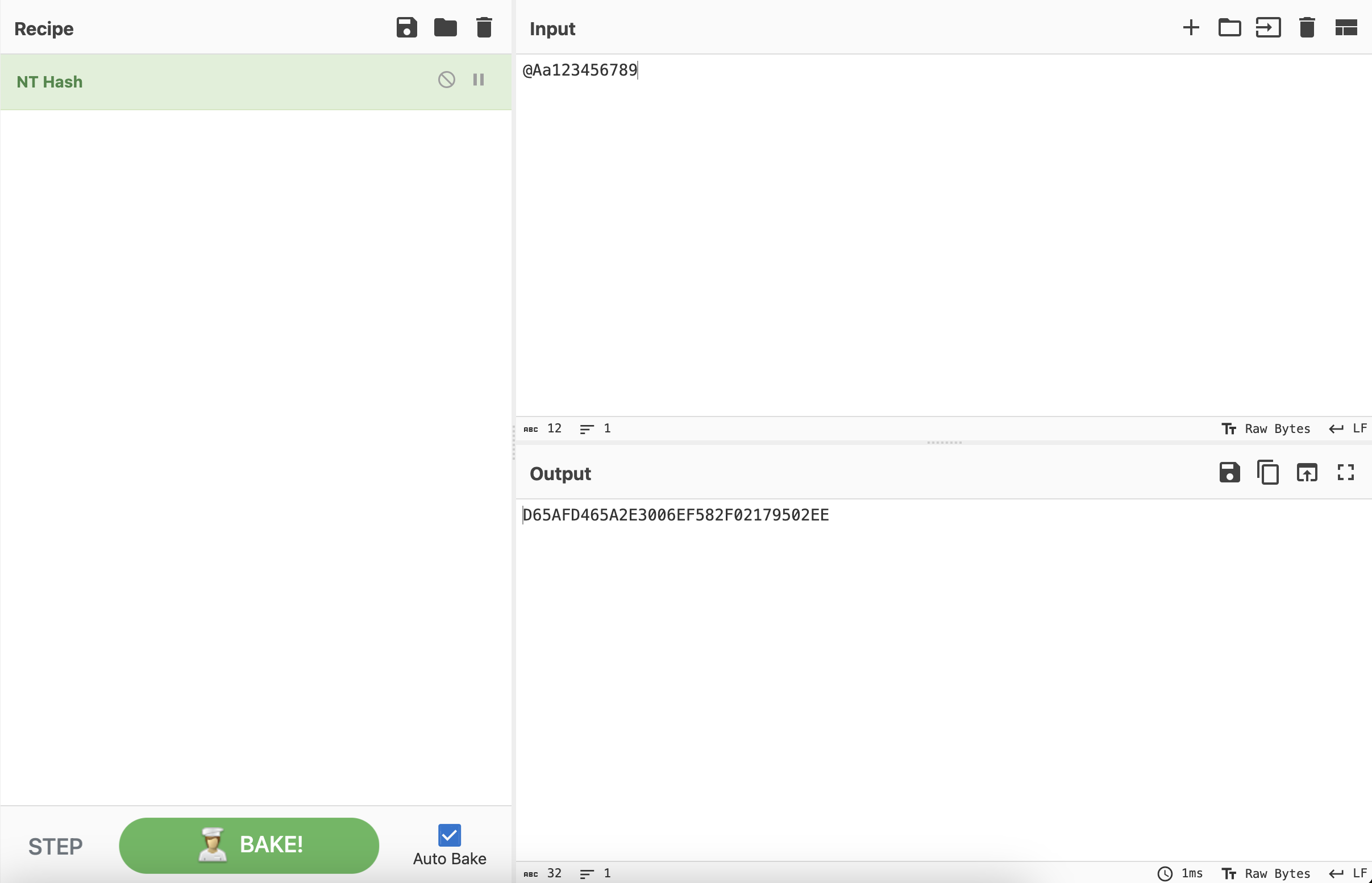
爆出来的管理员的密码是@Aa123456789,需要提交的是经过NTLM加密之后的结果,八神表演了一下Cyberchef的NTLM模块。

会吐泡泡的鱼
好好好,应该是零解题,这么出是吧,发出来是想让大家避坑,出题人藏着掖着解题思路没啥意思。
打开附件查看图片:
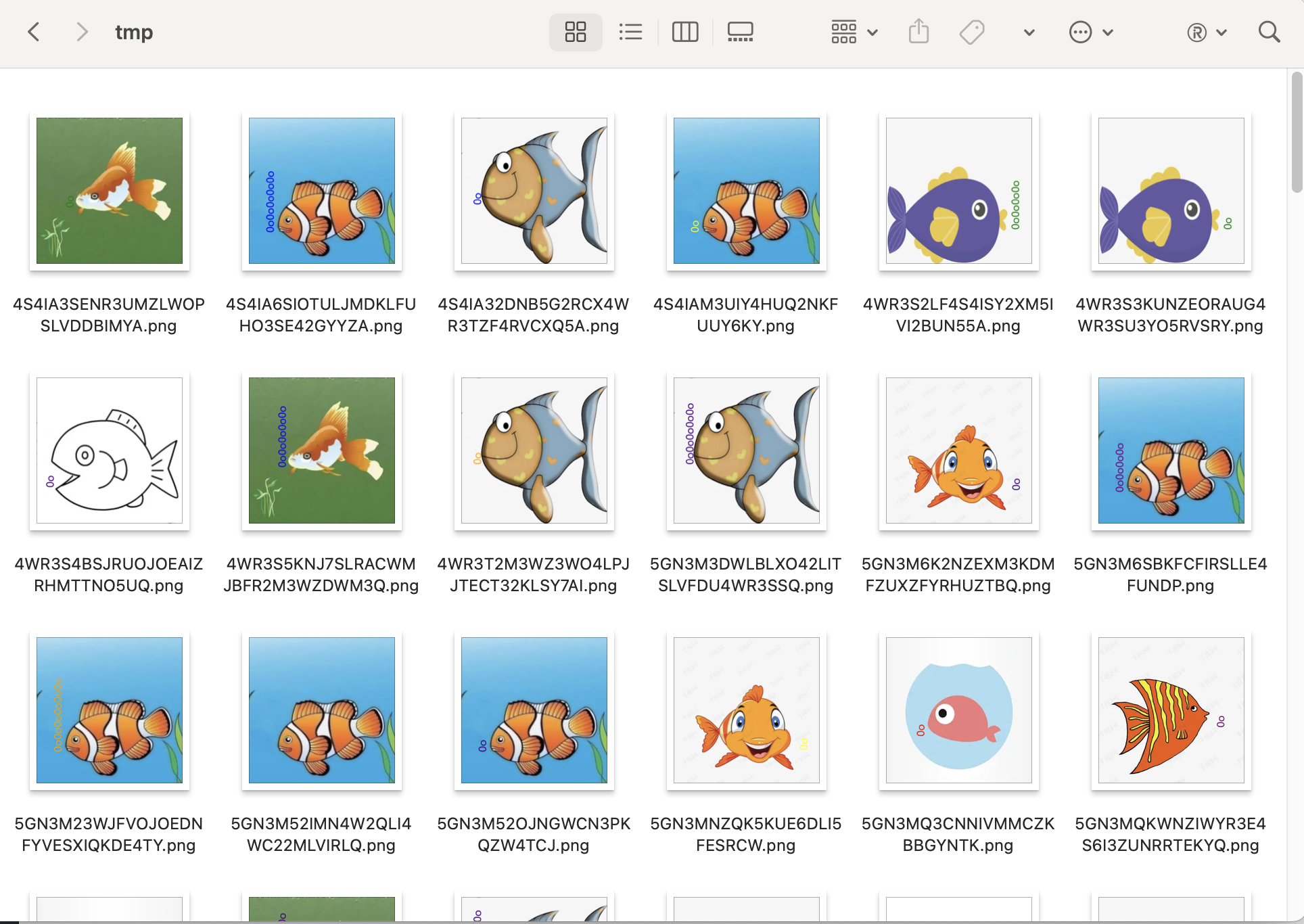
现有的信息如下:
- 一共有144张图片
- 每张图片都有不同数量和形状的泡泡
- 文件名可以base32解密
- 🤮🤮🤮
所有的文件名base32解密之后是
零fSVQI93aPkFe
SfcRp零Kr叁二nXa
Px壹四dWz零abvLq
1zpsvqjwu2D玖y
TEbZBh1三i0jgt
hkQP08Lpyv8KY
零kvIj七iqRJ肆NO
vwXdgC壹壹BUuG九
SUa一Xej零iVsG五
EWapqB14e四INj
r1f壹陆tOXbSJeF
bxsh零qa9zc四MF
ba壹yEV零Xgk4Wp
1YPXILbl0陆qUJ
J0NutgO三一LcsB
L1uSEBMs2七bzf
壹ie三cWgQTh4oz
零wNKMa7oT3nLI
零T叁VXLWU五gYMu
KsSi零Pr45XFRV
oRHyNd一sVj肆c贰
CRhT1UBe叁PIS六
零LyiD零zMe壹bmZ
lCDHre零五六hVaP
0GtdMVDn3x七La
fbX壹iV二贰PzhdW
壹mTnH肆壹SxwcYG
fsRuhK零零FnVg2
anNk壹gS一3TcQY
juyNn零一xctiR3
ndZC0z肆y9lifV
U零qHej五iEv5hW
R壹y壹ru柒YdXObj
tv零柒brci九WBCn
z零G5贰LVyltfdg
kx一QT叁UjEYKh3
XkjuGO零叁zg零yH
ecQF壹E2pCv五kq
dukM零wEGD4b零a
UTirLX零4oYC2g
零CbkQV0YPBl6j
VMaSCH0Z8dB柒z
p0nk贰zZ柒UoQXm
YHg零e捌FmIw5GN
X零Nk玖pPRJdnK八
零AxhaeNn八wtb叁
tVAN一K2E4eJyk
vu0Sb七贰nNhdgm
nF0Z贰jUqk0XJS
VJC零U9EBezlb柒
yRpOjx09零JEWo
ywrvKq1三u柒WaJ
H一LlgEpkx3T五C
一zHt贰jYhwnD捌d
CLrWx壹零b八gyXe
bEC零VWSf二m二vG
零BYj陆nM二EHWCl
零70WUBxkGJIDV
XP0Tldw九Zx五DY
壹p2Lh一FbvNmwi
w02xmhPp叁fWsG
ojp零V一EraIz二y
b0mKT零XSCVFG四
0零turZPz叁qbOg
一3tF8zCMQiLyX
零叁adiQhLxC九KW
z零uiW四六pTcedC
Sja零v8bBVYQ一T
NdJ1magx26XDe
T零ph九一Xkrxzal
J0drsB7t8mxve
WXCD零Rios六七PJ
UtwuTSL零a贰肆jx
壹uMO一VbBX零Gfn
bKgUHe一v壹M2od
RzZl1壹gP壹hwMB
零UNhePBcqgK伍柒
eHb0sp陆3KkmNC
FbkRYX壹e叁玖Ppa
零wHcymAh六1uDW
HB零44CAVjOJDQ
f零eq2Jhk陆gulr
S零WoXi6ERh0Ib
fqbP零9MC6RKln
pYf0nNtk陆yMr六
0sz一九mPvgrJad
xNRV壹fskQ零q9S
AaY壹K零custRV2
LeU零零coM玖DFVJ
WBH0K柒5smEeIN
DWmJrd零o七陆PFT
wxRbaSgc零2s八z
nsYV01NvhQ6TP
sCGdc1三BkOx1L
mFtodLBsC零D肆柒
n1D2OVPHF三mAt
零yZnIvmCasK三陆
Z一1fY肆aRpPzEQ
UKMbzxtZ零rl二壹
零FdqDl八gtf玖Zm
壹零wgqoJfAOzR叁
mf壹四tuTI3OKHg
z零BECbvP1TjJ8
零AVnQlGd伍捌fEb
OEwNUmBP一01Tp
Y0GIzDXm陆E肆hq
PTm0ZLbJki玖贰f
Y零qu二X五xcRwmk
uyKswr1E0mF柒p
UzmW一r三P二JTaD
nIBTUv零捌PKSl2
Ni0m陆BWtD9Uvz
g0KRFArE六Px5z
i零bATuh贰Yg9Sp
UFpPi1Bg零V0mx
一oChzmDW壹伍Ext
U零V1abeutg零lm
ye零SxW零JB七jIF
NAH零ybtoI4C壹w
vkwzI0fr1Ki七n
零cjmTVy六Bf8IZ
i零3EecRQWdj8P
yHBaP0hpL七k7I
tMs0haDgJq零8k
h零uXipD1壹QZnd
qAScCZtRHP07壹
S01nlda肆EbpDv
cVsdXtvGA零伍零z
L0ikUvJy捌Pj0q
Wo零Mb四Un三kXmI
FyJXI零x叁mA4YO
gKxMt零LBvl零h五
Rhizlu零1mn五Qs
XRl壹aygbx1Q八d
0KVD5iQWUv4PT
Up零四xtoOanRf八
rN0LF三wBo3PgS
dF0r九LimhHRT9
ox零mjMYa5SO玖d
NjS0A伍xMeF三wi
零lvXWwsKD五t壹J
KvBDhY零A捌cX六S
零zAQDTFKY8Z4o
一nDlwFevs二aC0
包含中文数字和阿拉伯数字,可以发现每行图片的数字范围是1-144,那么应该就是图片的排序方式了🫤
根据这个规律给每张图片修改名称:
# -*- coding: utf-8 -*-
# @Author : 1cePeak
import os
import base64
import string
import cn2an
# 获取指定目录下的文件列表
directory = './tmp'
files = os.listdir(directory)
for file in files:
original_filename = file # 保留原始文件名
padding = ''
while True:
try:
# 解码文件名并转换为UTF-8编码
decoded_data = base64.b32decode(original_filename[:-4] + padding).decode('utf8')
print(decoded_data)
# 创建一个新的文件名,将中文数字字符转换为阿拉伯数字
new_filename = ''
for char in decoded_data:
if char in string.digits:
new_filename += char
elif char not in string.printable:
new_filename += str(int(cn2an.cn2an(char)))
# 构建新文件的完整路径
new_file_path = os.path.join(directory, new_filename + '.png')
# 重命名文件
os.rename(os.path.join(directory, original_filename), new_file_path)
break # 成功重命名文件后退出循环
except Exception as e:
# 如果解码和转换失败,继续尝试添加等号("=")
padding += '='
然后根据修改好名称之后的图片,数一下每张图片泡泡的数量。
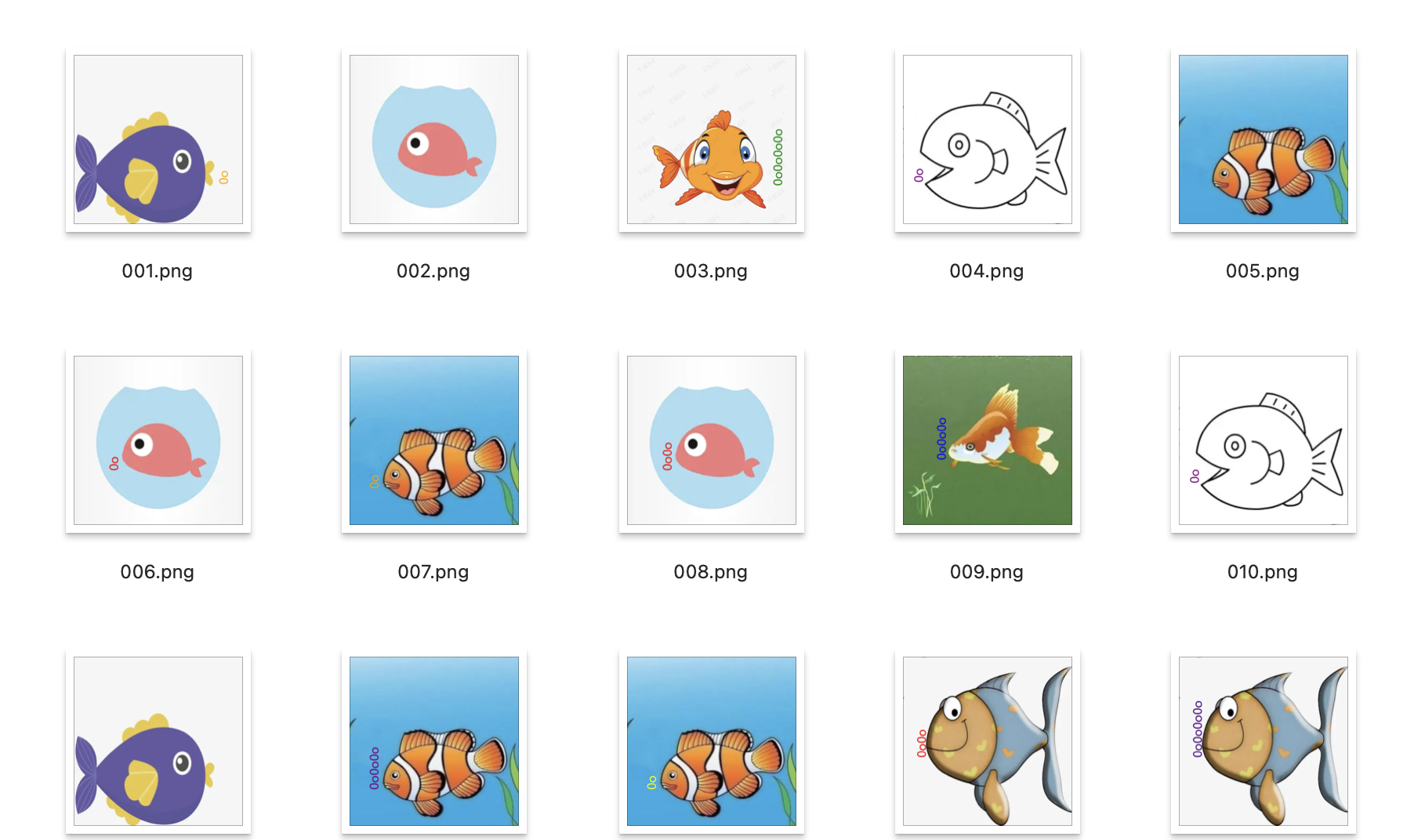
提取出来的结果是
104101123103124106173041041041146061163150137142165142142154063163137142165142142154063163137146061163150137150141150141150141150141041041041175
字符串没有超过8的数字,猜测是八进制,转换为ascii之后得到flag
# -*- coding: utf-8 -*-
# @Author : 1cePeak
# 输入的八进制数字字符串
octal_string = "104101123103124106173041041041146061163150137142165142142154063163137142165142142154063163137146061163150137150141150141150141150141041041041175"
# 将八进制字符串按每三个字符分组
octal_groups = [octal_string[i:i+3] for i in range(0, len(octal_string), 3)]
# 将每组的八进制数转换为ASCII字符
ascii_string = ''.join([chr(int(octal, 8)) for octal in octal_groups])
print(ascii_string)
最终得到:
DASCTF{!!!f1sh_bubbl3s_bubbl3s_f1sh_hahahaha!!!}