好一个All in RSA大赛😏
看之前可以观摩下去年的经典赛题传送门
再来看看今年的赛题背景和赛题任务介绍。
赛题背景
近年来,三明市探索数据要素应用创新,在时空数据产业方面,坚持以深化供给侧结构性改革为主线,布局通导遥卫星与低空经济产业链,不断推动产业链上下游企业的紧密合作,推广探索无人机应用,不断筑牢时空数据基础底座,将公共数据与地理空间数据融合,实现全市“一张图”,推进公共数据“聚、通、用”,在突破核心技术、打造特色优势产业、培育时空数据企业等方面取得了一定成效。
2025数字中国创新大赛数字安全赛道时空数据安全赛题暨三明市第五届“红明谷”杯大赛将聚焦时空数据安全领域,运用往届赛事沉淀的成果,以三明市网络安全靶场作为支撑第五届红明谷杯赛事的基础平台,吸引全国的优秀团队和人才参与,共同探索时空数据安全的新技术和新模式。
赛题任务
大赛围绕卫星应用、无人机应用等领域的时空数据安全管理,关注数据隐私泄露、黑客攻击、应用场景创新和安全应用开发,强化针对时空数据安全防护的安全技术和措施,建立针对多种时空数据应用场景下的创新解决方案。同时,提升时空数据安全产业发展过程中相关企业和个人对时空数据安全的认知与防护意识。
简单的仓库
先注册一个账号看看功能点,发现是guest权限。在充值金额的时候把POST数据中的permission字段改成admin,这样就成了vip权限。再使用下载功能,发现/api/files可以路径穿越任意读文件。
异常行为溯源
解题最重要的是思路,思路对了用什么方法都可以做出来。
一看到pcap流量包我就情不自已的strings了,为什么呢?因为高端的食材往往只需要采用最朴素的烹饪方式。流量肯定会有数据传输,那么往往可以直接strings或者binwalk来非预期。
1
|
strings network_traffic.pcap > 1.txt
|

然后base64解码得到传输的消息
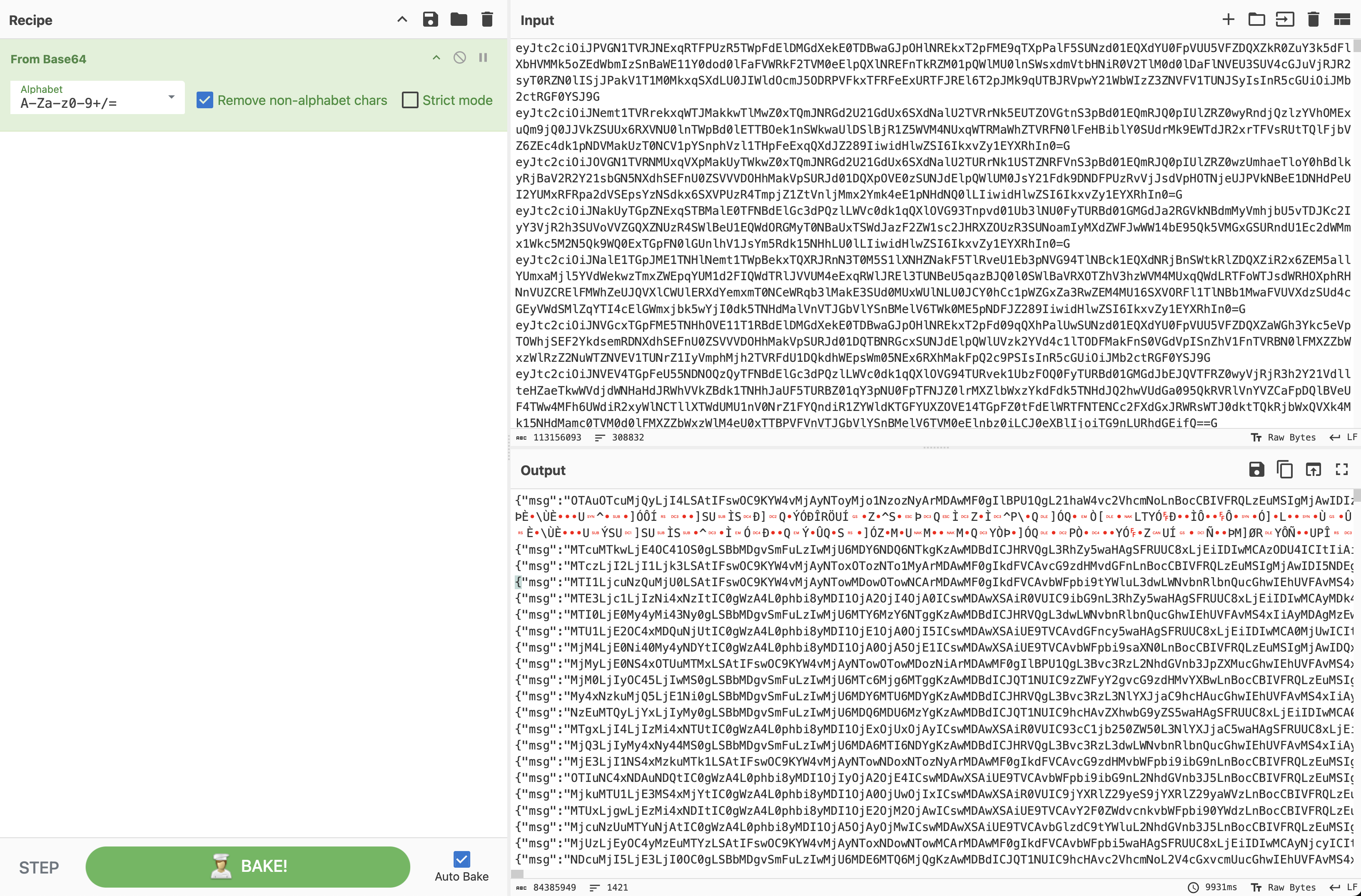
写正则提取所有msg字段的数据,再base64解码一次。可以看到这是Nginx的日志,到这里应该就很清晰了,分析日志里的攻击数据。

根据题目描述,需要找出攻击IP,简单粗暴的方法就是找到出现次数最多的IP,直接写正则提取所有IP,统计出现的次数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# -*- coding: utf-8 -*-
# @Author : 1cePeak
import re
from collections import Counter
ip_pattern = re.compile(r'^(\d+\.\d+\.\d+\.\d+)')
ips = []
with open('3.txt', 'r') as file:
for line in file:
match = ip_pattern.search(line)
if match:
ips.append(match.group(1))
ip_counts = Counter(ips)
# 找到出现次数最多的IP并输出
if ips:
most_common_ip, max_count = ip_counts.most_common(1)[0]
print(f"{most_common_ip} {max_count}")
else:
print("No IP addresses found.")
|
可以看到35.127.46.111这个IP出现了4次,md5(ip)提交之后成功拿下一血。
数据校验
数据校验题目说明
注:题目数据均为随机生成
字段说明
Serial_Number:序列号
UserName:用户名,格式必须为 User- +字符串
UserName_Check:用户名的32位小写MD5值
Password:用户密码,密码中只能出现大写字母、小写字母和数字
Password_Check:密码的32位小写MD5值
IP:用户的IP地址
Signature:用户签名值,对用户名采用ECDSA算法进行数字签名
题目要求
选手需要结合字段说明,编写脚本处理题目数据,找到附件中所有不合规的数据
请将所有不合规数据的序列号按照从大到小的顺序用 _
连接后MD5并包上flag{}
提交。例如,不合规的数据序列号为6、38、1680,则连接后为 6_38_1680,
flag为flag{1ffcb6d1c2108cd54a7743a6f91a289a}
直接把题目描述和data.csv里面的数据格式扔给chatGPT或者Deepseek就行。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
|
# -*- coding: utf-8 -*-
# @Author : 1cePeak
import pandas as pd
import hashlib
import re
import os
import base64
from ecdsa import VerifyingKey, BadSignatureError
def md5_hash(text):
return hashlib.md5(text.encode('utf-8')).hexdigest()
def validate_username(username):
return username.startswith('User-')
def validate_password(password):
return bool(re.fullmatch(r'[a-zA-Z0-9]+', password))
def validate_ip(ip):
ip_pattern = re.compile(r'^(?:[0-9]{1,3}\.){3}[0-9]{1,3}$')
if not ip_pattern.match(ip):
return False
parts = list(map(int, ip.split('.')))
return all(0 <= part <= 255 for part in parts)
def verify_signature(username, signature, key_path):
try:
with open(key_path, 'rb') as f:
vk = VerifyingKey.from_pem(f.read())
decoded_signature = base64.b64decode(signature)
vk.verify(decoded_signature, username.encode('utf-8'))
return True
except (BadSignatureError, ValueError, FileNotFoundError, base64.binascii.Error):
return False
def main():
# 读取数据
df = pd.read_csv('data.csv')
invalid_serials = []
for index, row in df.iterrows():
serial = row['Serial_Number']
username = row['UserName']
username_check = row['UserName_Check']
password = row['Password']
password_check = row['Password_Check']
ip = row['IP']
signature = row['Signature']
# 1. 校验 UserName 格式
if not validate_username(username):
invalid_serials.append(serial)
continue
# 2. 校验 UserName 的 MD5 值
if md5_hash(username) != username_check:
invalid_serials.append(serial)
continue
# 3. 校验 Password 格式
if not validate_password(password):
invalid_serials.append(serial)
continue
# 4. 校验 Password 的 MD5 值
if md5_hash(password) != password_check:
invalid_serials.append(serial)
continue
# 5. 校验 IP 地址格式
if not validate_ip(ip):
invalid_serials.append(serial)
continue
# 6. 校验签名
key_path = f"ecdsa-key/{serial}.pem"
if not verify_signature(username, signature, key_path):
invalid_serials.append(serial)
if invalid_serials:
# 按照从小到大排序
invalid_serials.sort()
print(invalid_serials)
# 生成 flag
joined_serials = '_'.join(map(str, invalid_serials))
print(joined_serials)
flag = f"flag{{{md5_hash(joined_serials)}}}"
print("Flag:", flag)
else:
print("所有数据均符合要求。")
if __name__ == '__main__':
main()
|
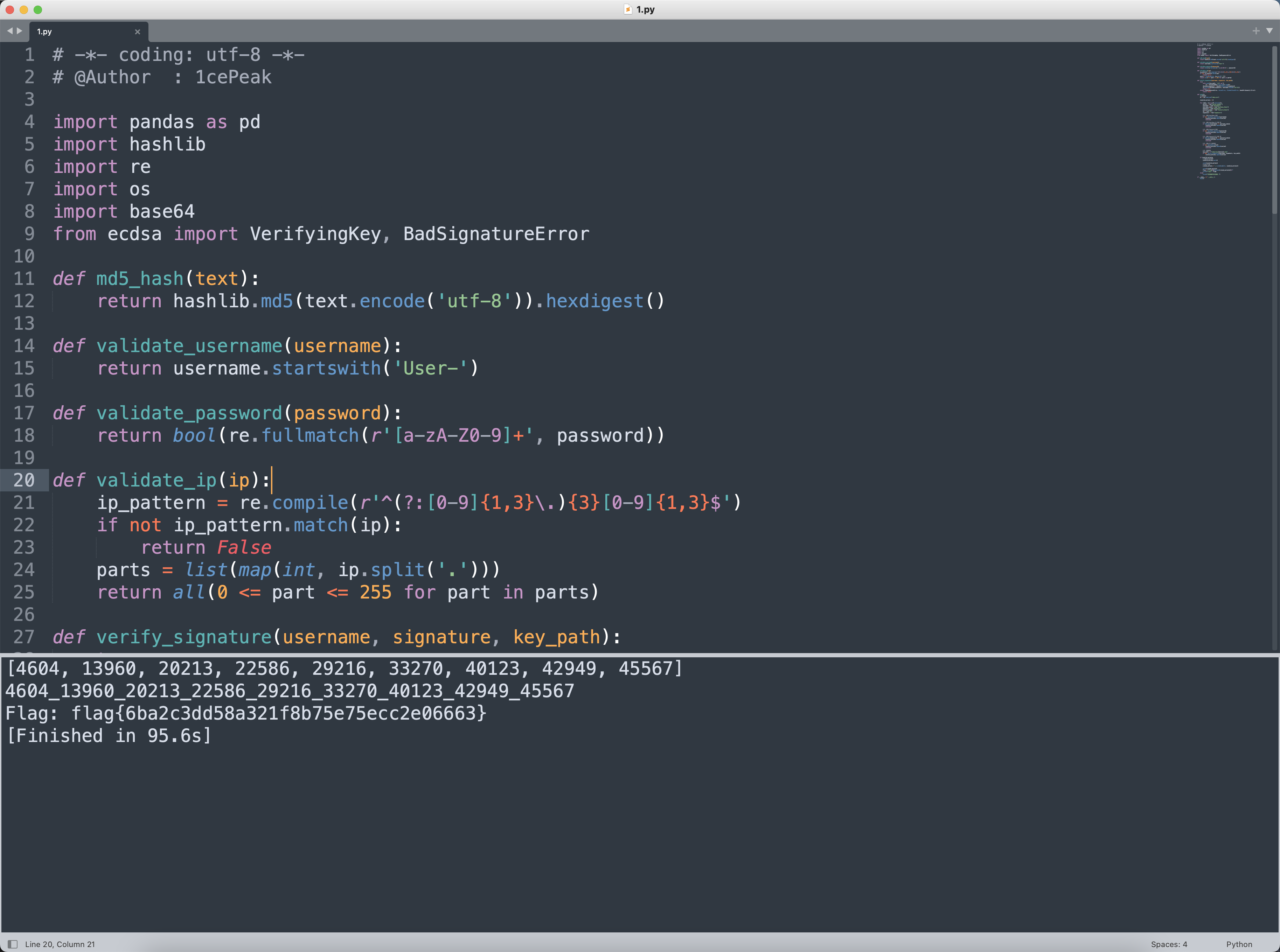
这次chatGPT和Deepseek调教的比较慢,没抢到前三血哈哈0rz
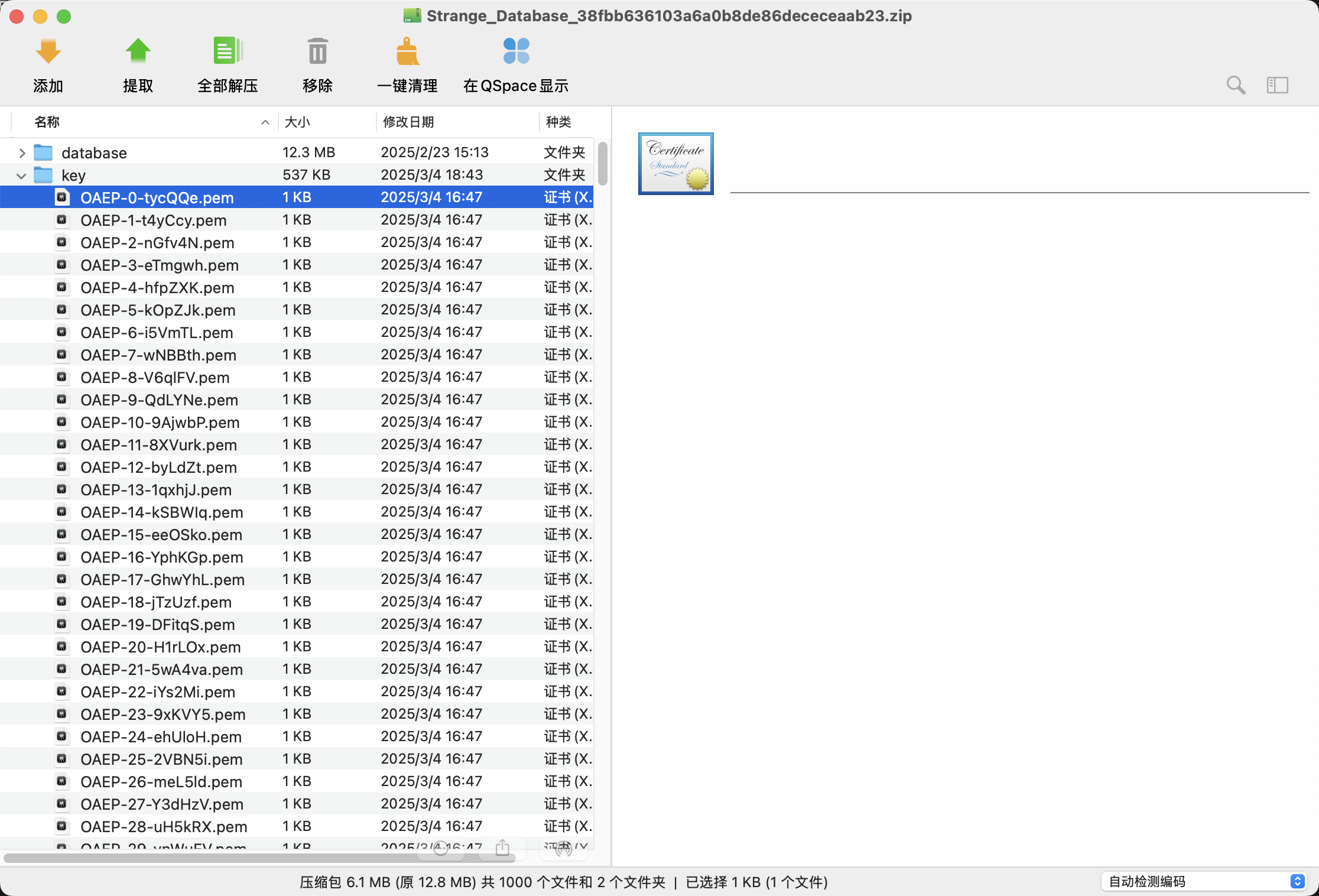
Strange_Database
给了两个文件夹,500个key和500个database文件。
 打开db文件查看详细内容
打开db文件查看详细内容
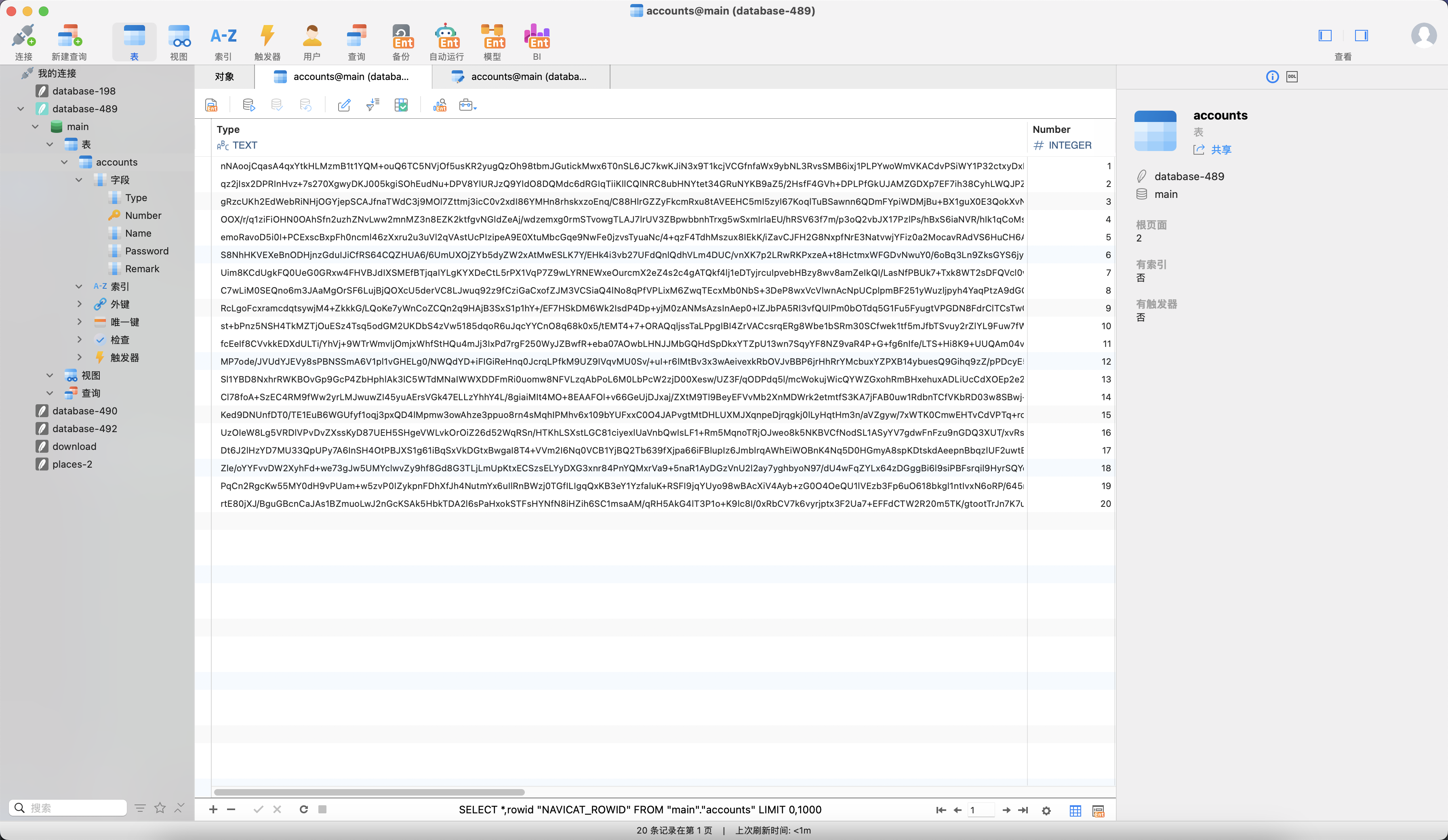
发现有五个字段
1
2
3
4
5
6
7
|
table accounts accounts CREATE TABLE accounts (
Type TEXT,
Number INTEGER PRIMARY KEY,
Name TEXT NOT NULL,
Password TEXT,
Remark TEXT CHECK(Remark GLOB '[A-Za-z0-9=/]*')
)
|
再看一下key文件夹内容。
打开一个pem文件看看,一共有500个pem文件。
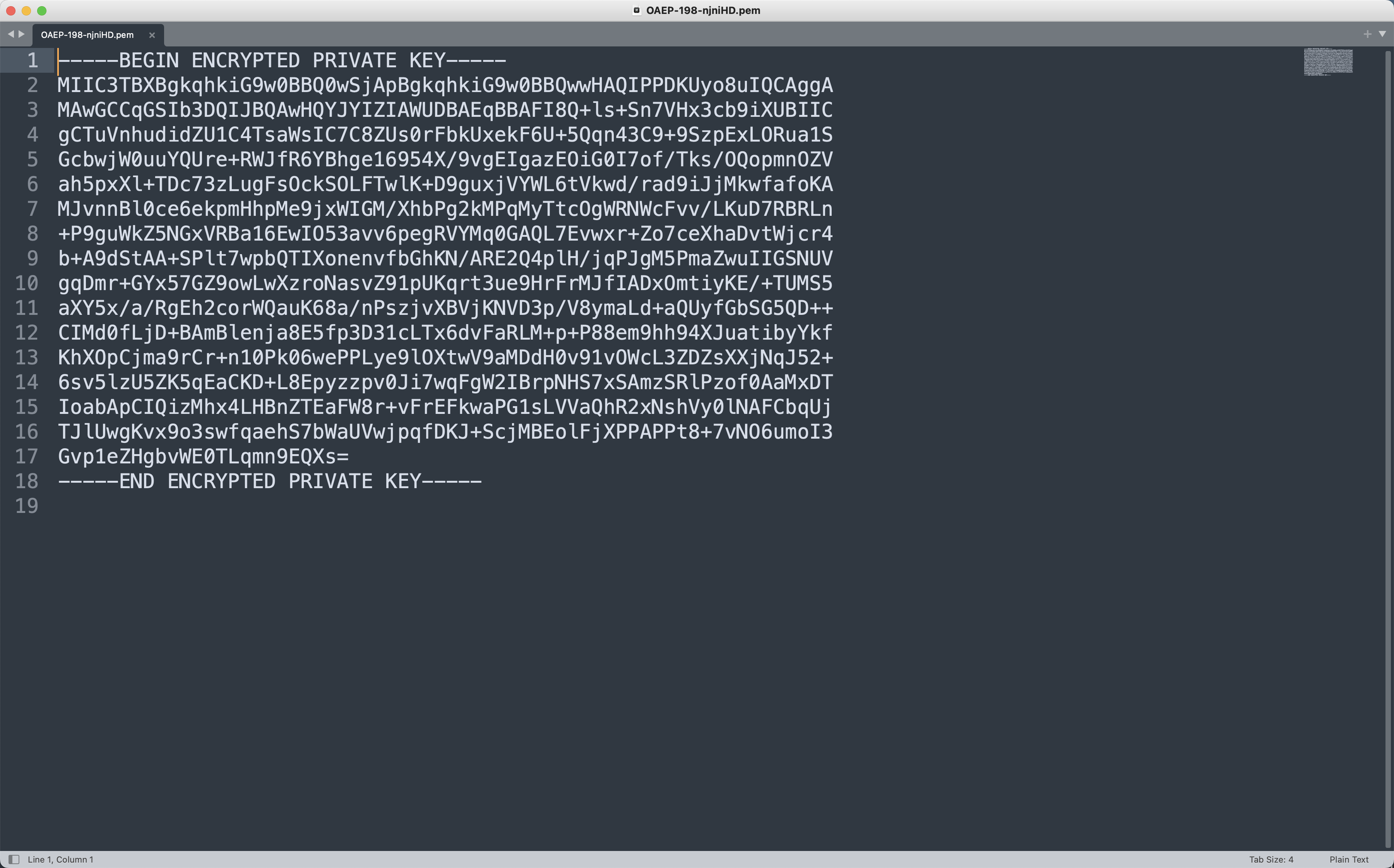
发现给的是带密码的私钥,观察一下文件名,中间数字应该是对应的db序号,后六位应该是私钥的密码。
看起来用私钥pem文件来解密db数据库就行,那么还是让无敌的Deepseek来替我动手吧!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
|
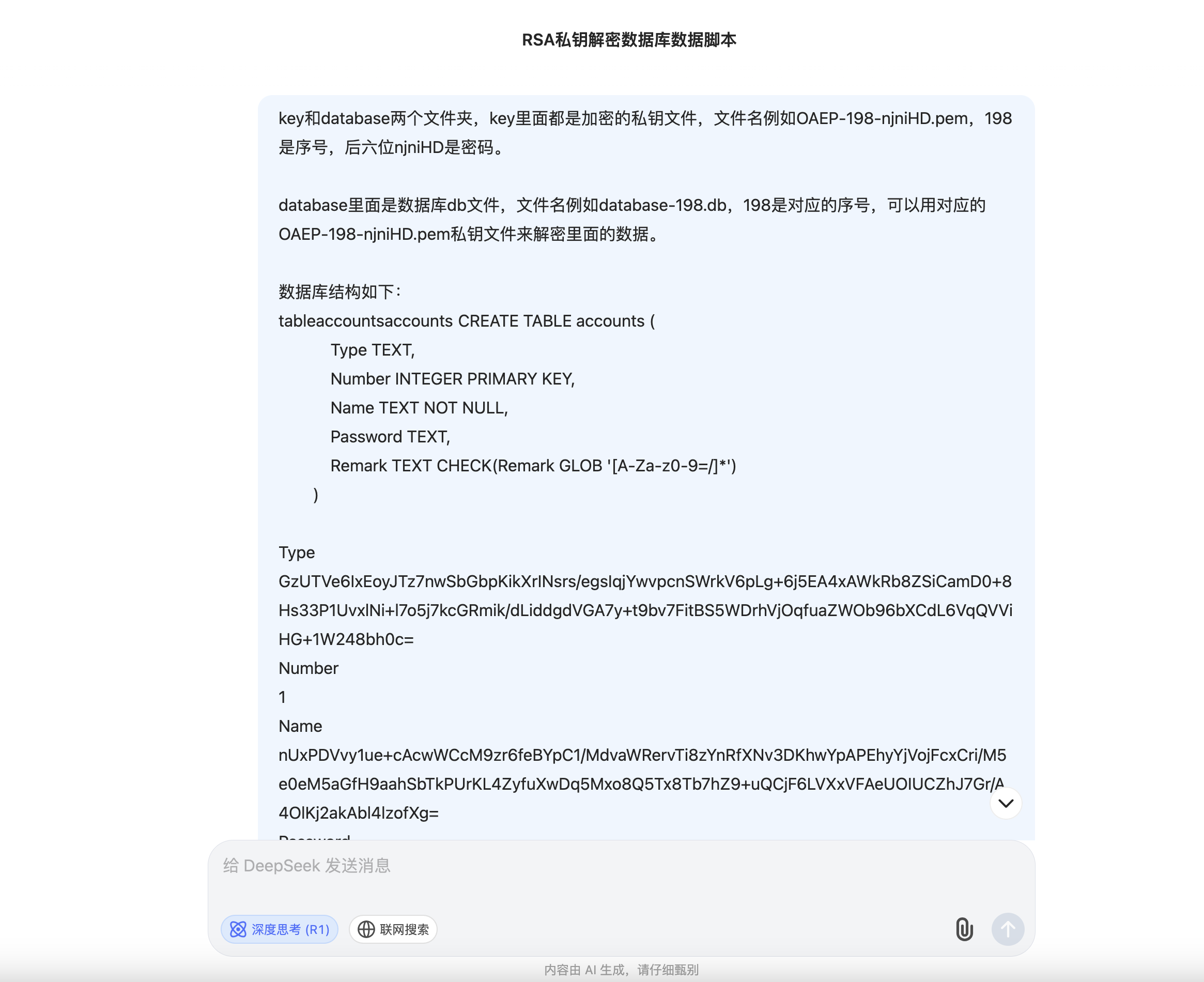
# -*- coding: utf-8 -*-
# @Author : 1cePeak
import os
import re
import sqlite3
import csv
import base64
from cryptography.hazmat.primitives import serialization
from cryptography.hazmat.primitives.asymmetric import padding
from cryptography.hazmat.primitives import hashes
from cryptography.hazmat.backends import default_backend
def decrypt_private_key(key_path, password):
"""使用密码解密PEM格式的私钥"""
with open(key_path, "rb") as f:
return serialization.load_pem_private_key(
f.read(),
password=password.encode(),
backend=default_backend()
)
def rsa_decrypt(private_key, ciphertext_b64):
"""使用RSA-OAEP解密Base64编码的密文"""
ciphertext = base64.b64decode(ciphertext_b64)
return private_key.decrypt(
ciphertext,
padding.OAEP(
mgf=padding.MGF1(algorithm=hashes.SHA1()),
algorithm=hashes.SHA1(),
label=None
)
).decode('utf-8')
def process_database(db_path, private_key):
"""解密数据库中的所有记录"""
conn = sqlite3.connect(db_path)
cursor = conn.cursor()
cursor.execute("SELECT Type, Number, Name, Password, Remark FROM accounts")
return [
(
rsa_decrypt(private_key, row[0]), # Type
row[1], # Number
rsa_decrypt(private_key, row[2]), # Name
rsa_decrypt(private_key, row[3]), # Password
rsa_decrypt(private_key, row[4]) # Remark
) for row in cursor.fetchall()
]
def main():
key_dir = "key"
db_dir = "database"
output_csv = "decrypted_results.csv"
# 创建CSV文件并写入标题
with open(output_csv, 'w', newline='', encoding='utf-8') as csvfile:
csv.writer(csvfile).writerow(['Type', 'Number', 'Name', 'Password', 'Remark'])
# 按数字顺序处理0-499
for seq in range(500):
# 构造数据库文件名
db_file = f"database-{seq}.db"
db_path = os.path.join(db_dir, db_file)
# 跳过不存在的数据库文件
if not os.path.exists(db_path):
print(f"跳过不存在的数据库文件:{db_file}")
continue
# 查找对应的私钥文件
key_prefix = f"OAEP-{seq}-"
key_files = [
f for f in os.listdir(key_dir)
if f.startswith(key_prefix) and f.endswith(".pem")
]
if not key_files:
print(f"找不到序号 {seq} 的私钥文件")
continue
# 提取密码(取文件名最后6位前的内容)
key_file = key_files[0]
password = key_file.split("-")[-1].replace(".pem", "")[-6:] # 确保取最后6位
try:
# 加载私钥
private_key = decrypt_private_key(
os.path.join(key_dir, key_file),
password
)
except Exception as e:
print(f"解密私钥失败:{key_file},错误:{str(e)[:50]}...")
continue
# 处理数据库
try:
decrypted_data = process_database(db_path, private_key)
except Exception as e:
print(f"处理数据库失败:{db_file},错误:{str(e)[:50]}...")
continue
# print(decrypted_data)
# 追加写入CSV
with open(output_csv, 'a', newline='', encoding='utf-8') as csvfile:
writer = csv.writer(csvfile)
writer.writerows(decrypted_data)
print(f"已处理 {db_file} -> 保存 {len(decrypted_data)} 条记录")
if __name__ == "__main__":
main()
|
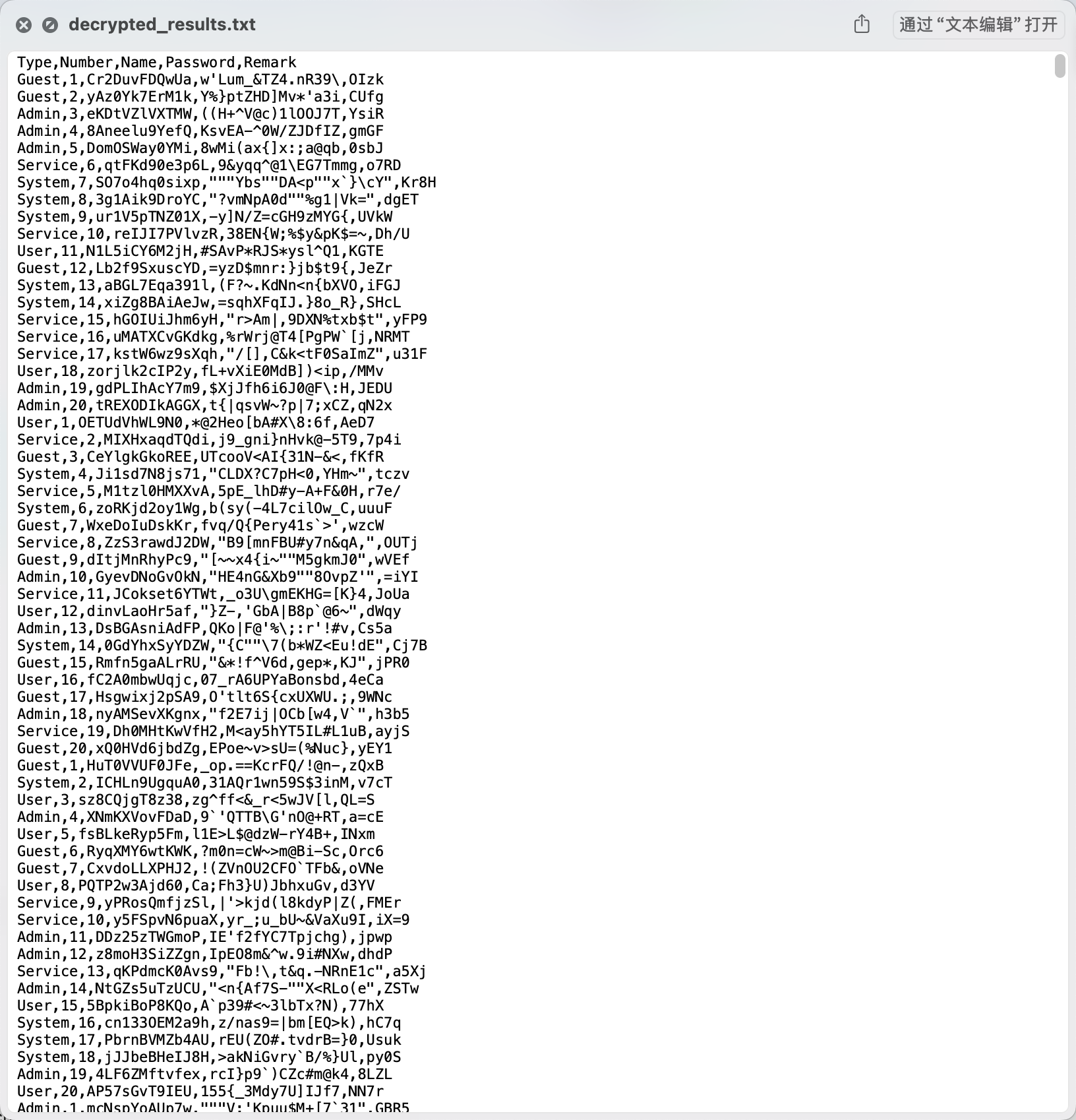
观察解密出来的数据库数据,一共有7个用户,重点关注一下Enc和Key用户的数据。
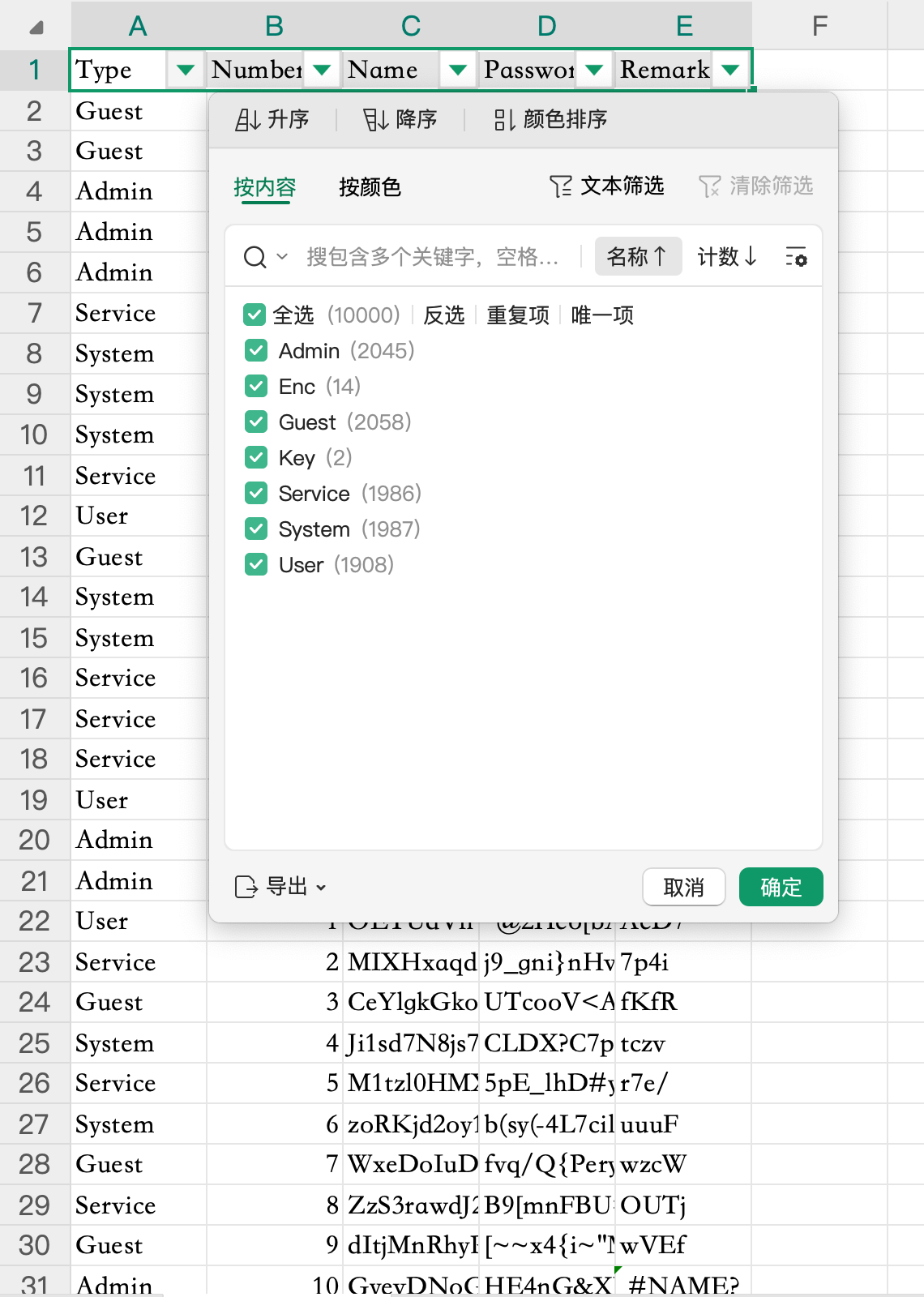
把Enc和Key用户所有Remark字段的数据提取出来
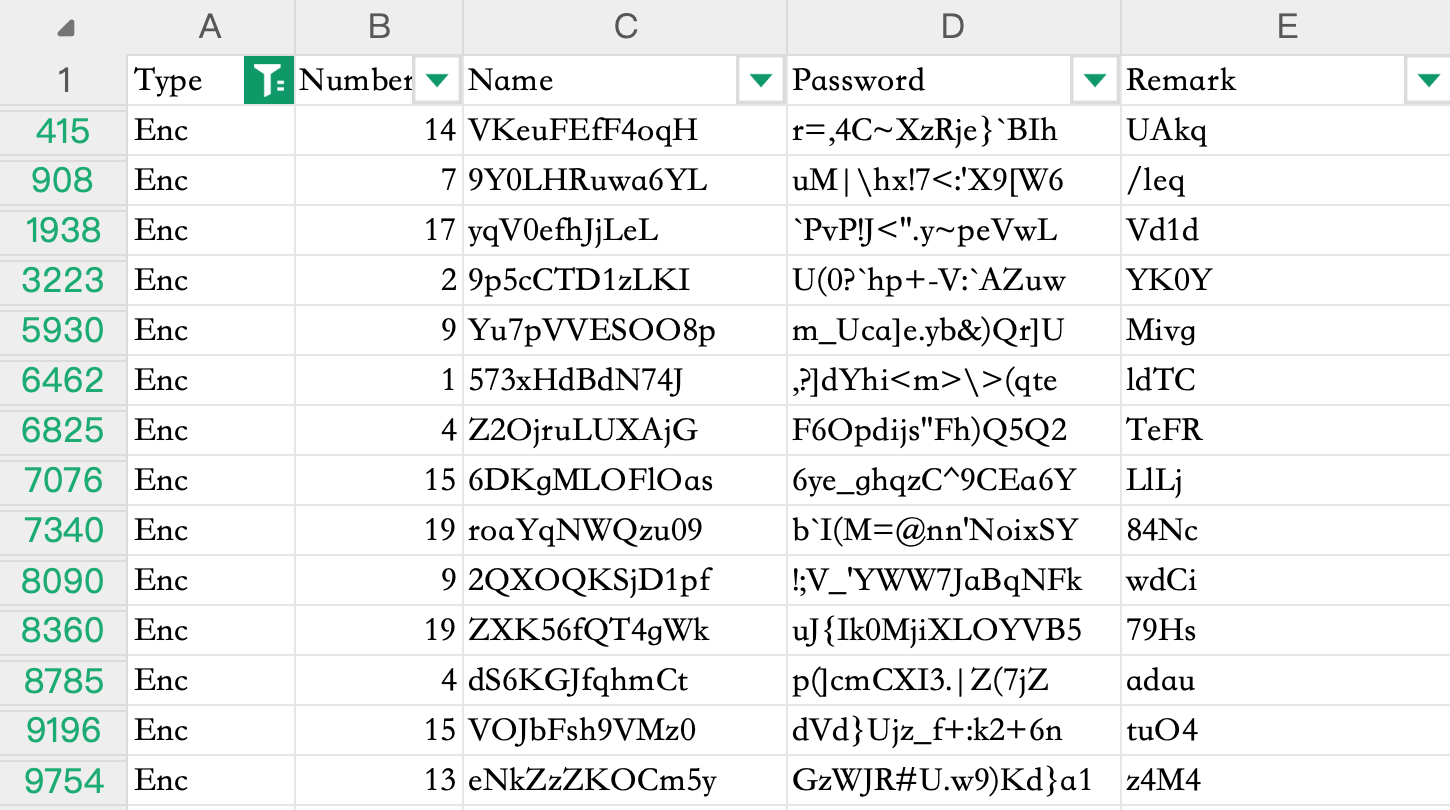

当看到Key用户的Remark字段数据拼接起来是Ic4unq1U的时候,就知道肯定没问题(i春秋),接下来就是解密Enc的密文了。
1
2
|
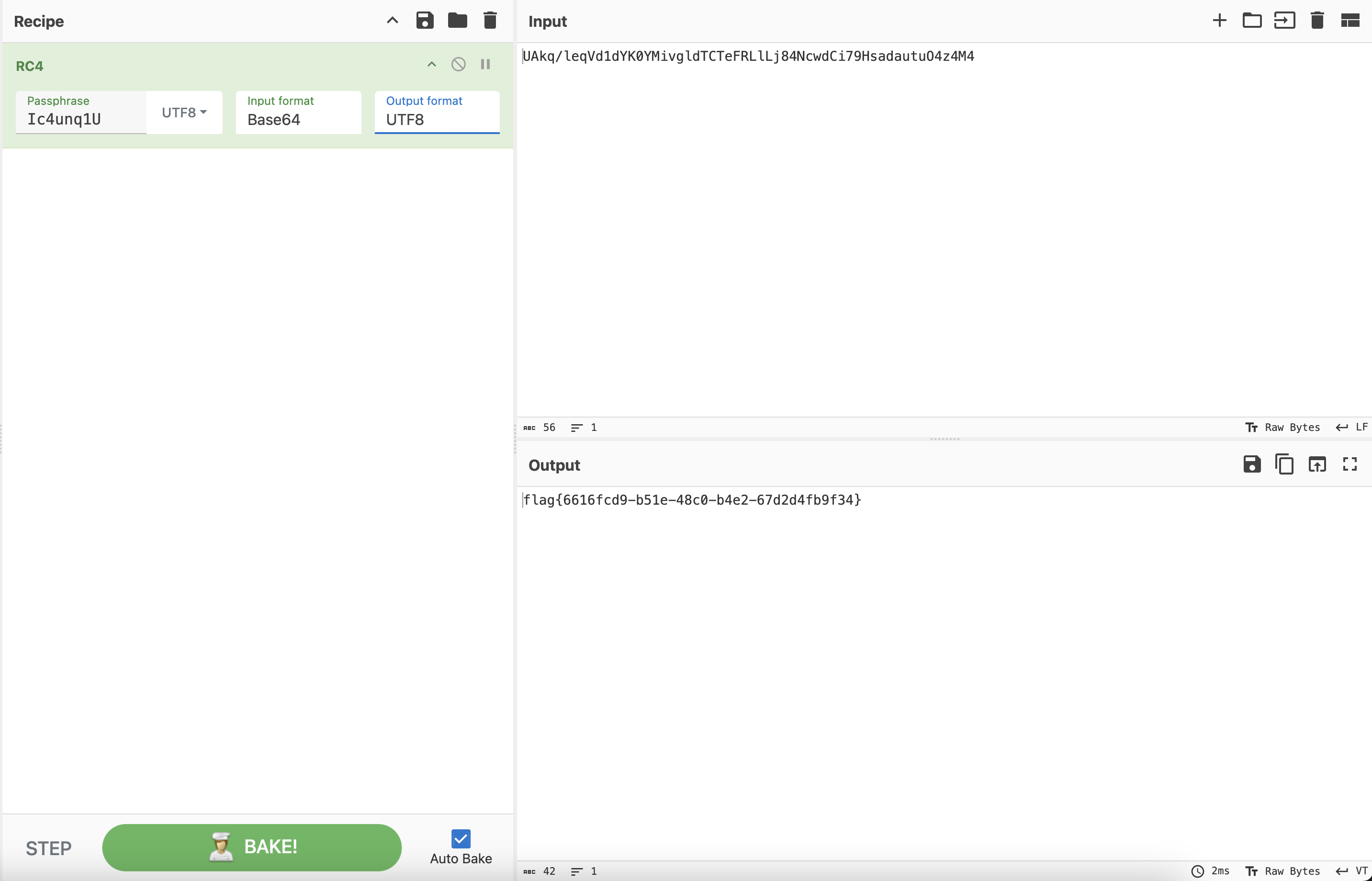
Enc:UAkq/leqVd1dYK0YMivgldTCTeFRLlLj84NcwdCi79HsadautuO4z4M4
key:Ic4unq1U
|
我选择无脑随波逐流一下
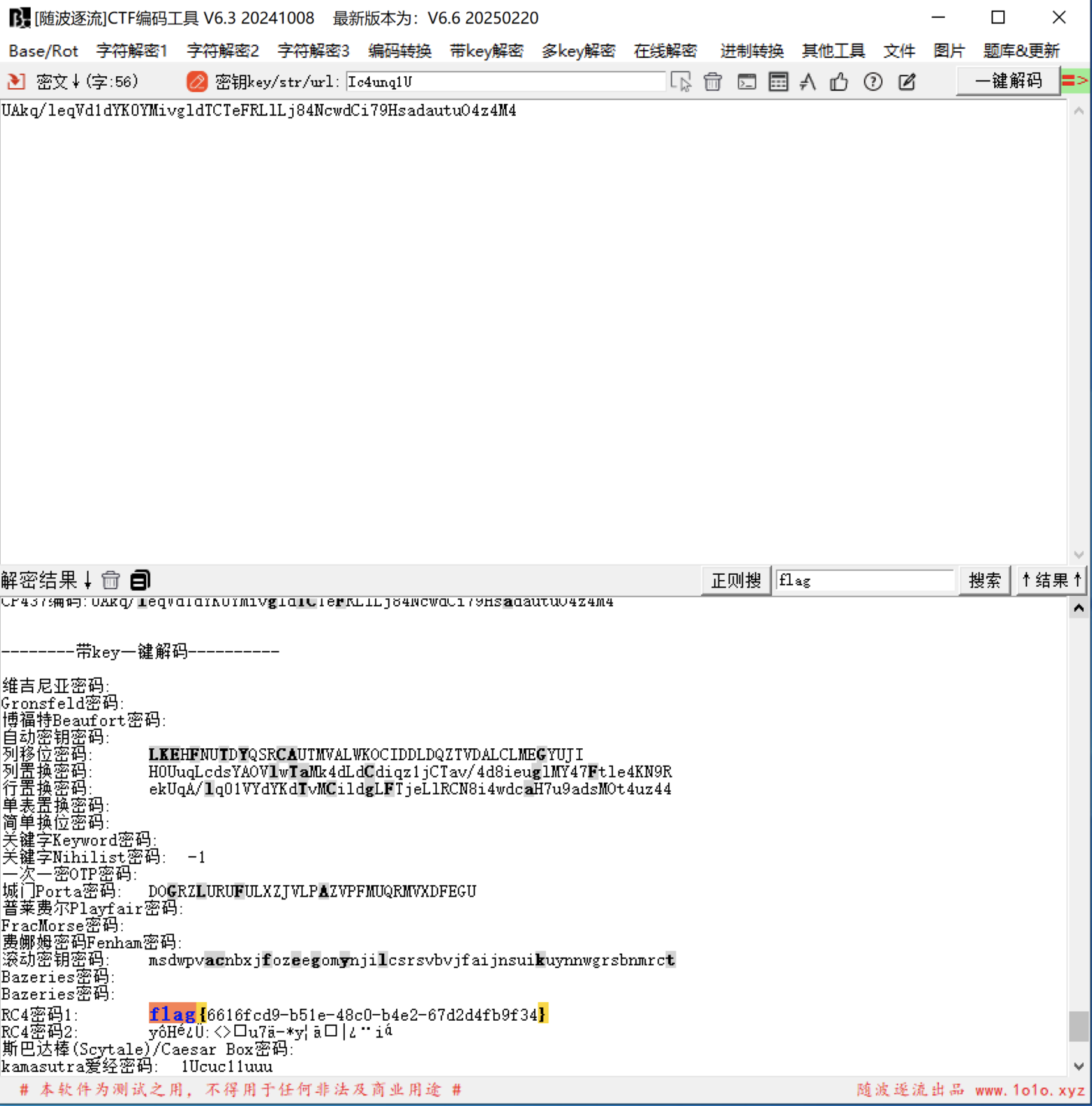
或者用Cyberchef也行
光速AK下班,天气这么好,该出去赏花啦🌸🌸🌸