还好这比赛在周末,Deepseek和chatGPT等一众AI用起来很丝滑,题量非常大,选手更像是MCP其中的一环😭
数据安全
模型安全
数据分析
溯源与取证
考题附件:https://pan.baidu.com/s/19Z4y4vI6yLLPLpbA-LSTmA?pwd=pkkh 提取码: pkkh 或者 https://www.123684.com/s/aL4BTd-2tGsA?提取码:tknR
考题解压密码:44216bed0e6960fa
溯源与取证-1
运维人员误删除了一个重要的word文件,请通过数据恢复手段恢复该文件,文件内容即为答案。
方法一
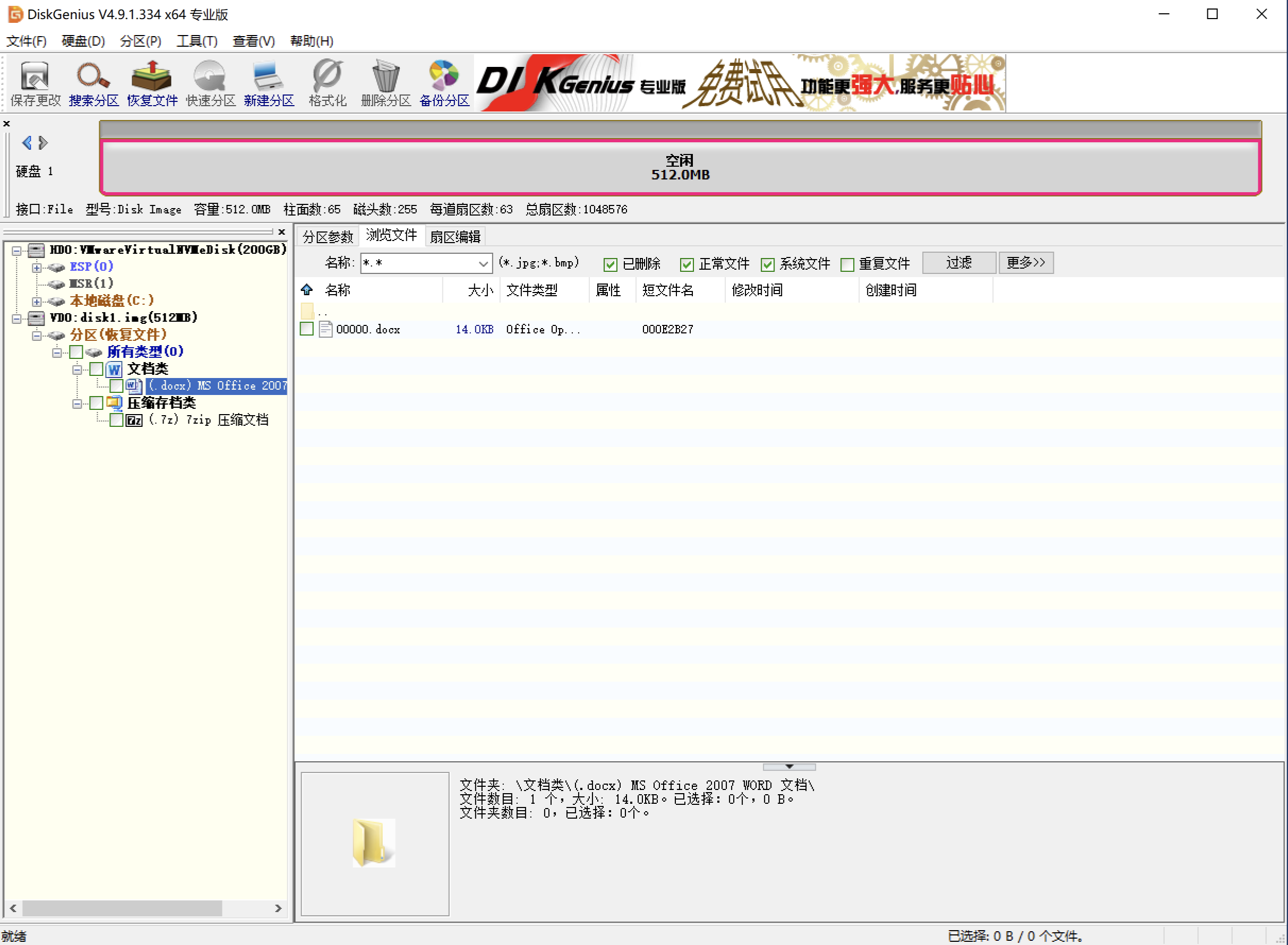
按部就班,使用DiskGenius挂载disk1.img文件,提取磁盘镜像中的文件。
方法二
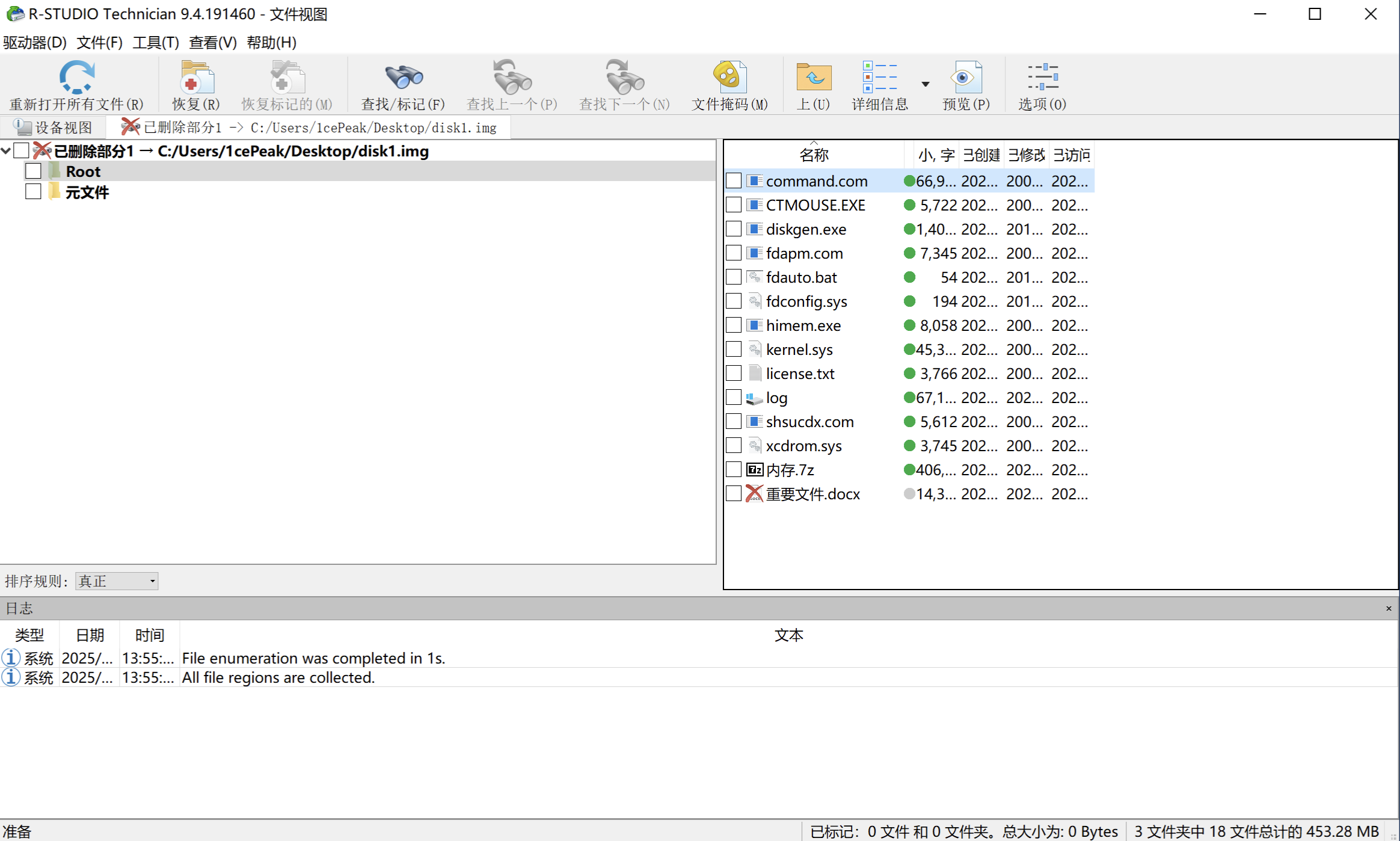
按部就班,使用R-Studio、Autopsy等取证工具挂载disk1.img文件,提取磁盘镜像中的文件。
方法三
暴力美学binwalk,根据文件结构分离所有文件。
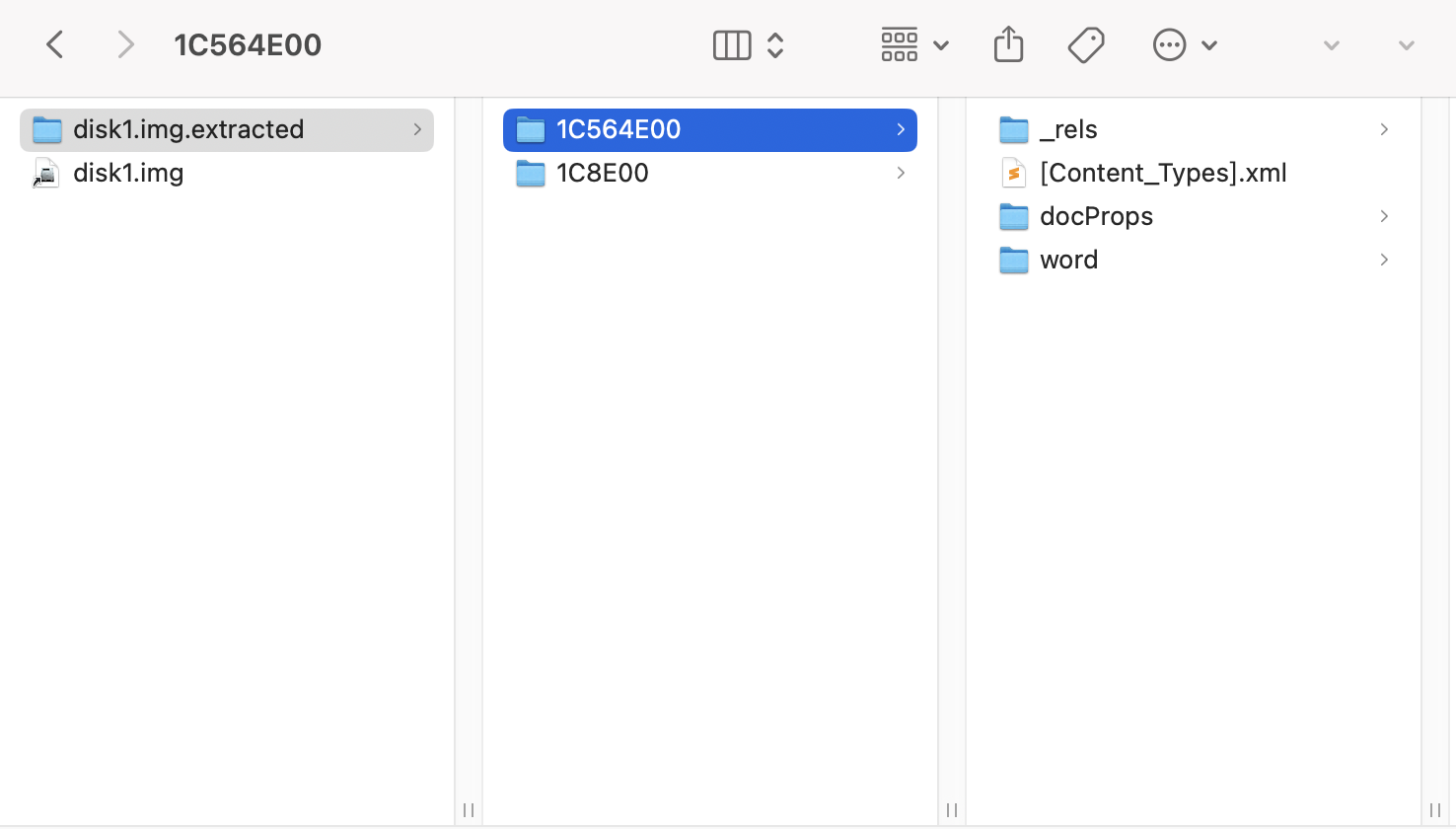
可以看到word文档的目录结构,查看文档的正文目录/word/document.xml,看到了很多又红又专的正能量好文。
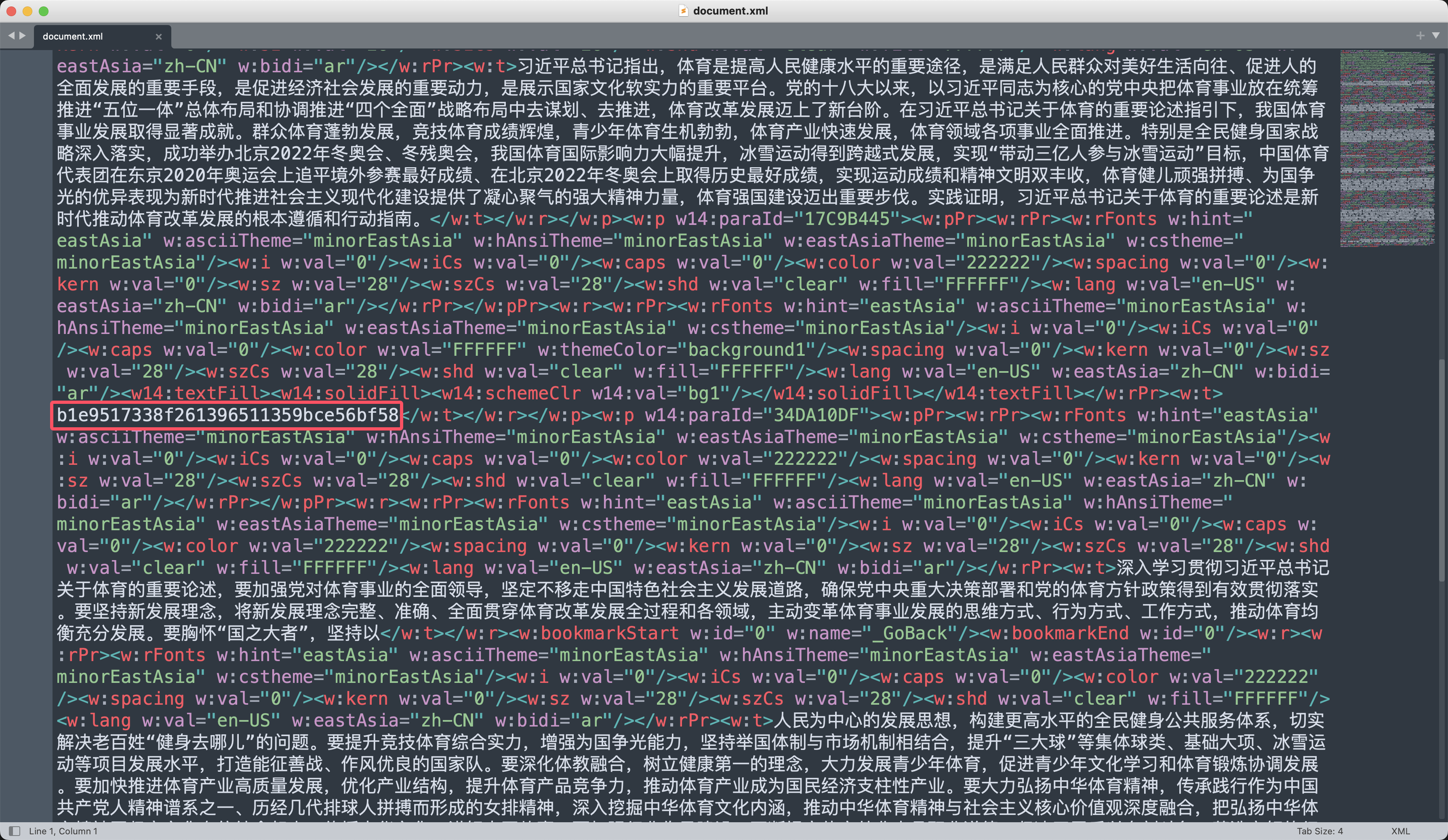
其中藏了32个字节的md5字符串b1e9517338f261396511359bce56bf58,提交即可,顺利拿下一血。✅
溯源与取证-2
服务器网站遭到了黑客攻击,但服务器的web日志文件被存放在了加密驱动器中,请解密获得该日志并将黑客ip作为答案提交。
题目描述是需要通过日志找到黑客的攻击IP,猜测是Nginx的access.log日志,而且肯定是用sqli-lab之类的靶场出的。接下来提取出disk1.img磁盘文件中的内存.7z,发现是Windows系统的镜像。
方法一
通过R-Studio来提取WIN-IRBP5Q8F25I-20250306-172341.raw镜像中的Nginx日志。
查看扫描之后的结果,发现有很多txt文档。
随便点开一个txt文档看看内容,发现真的是Nginx的access.log日志,并且看到了114.10.143.92这个IP,直接提交即可。✅
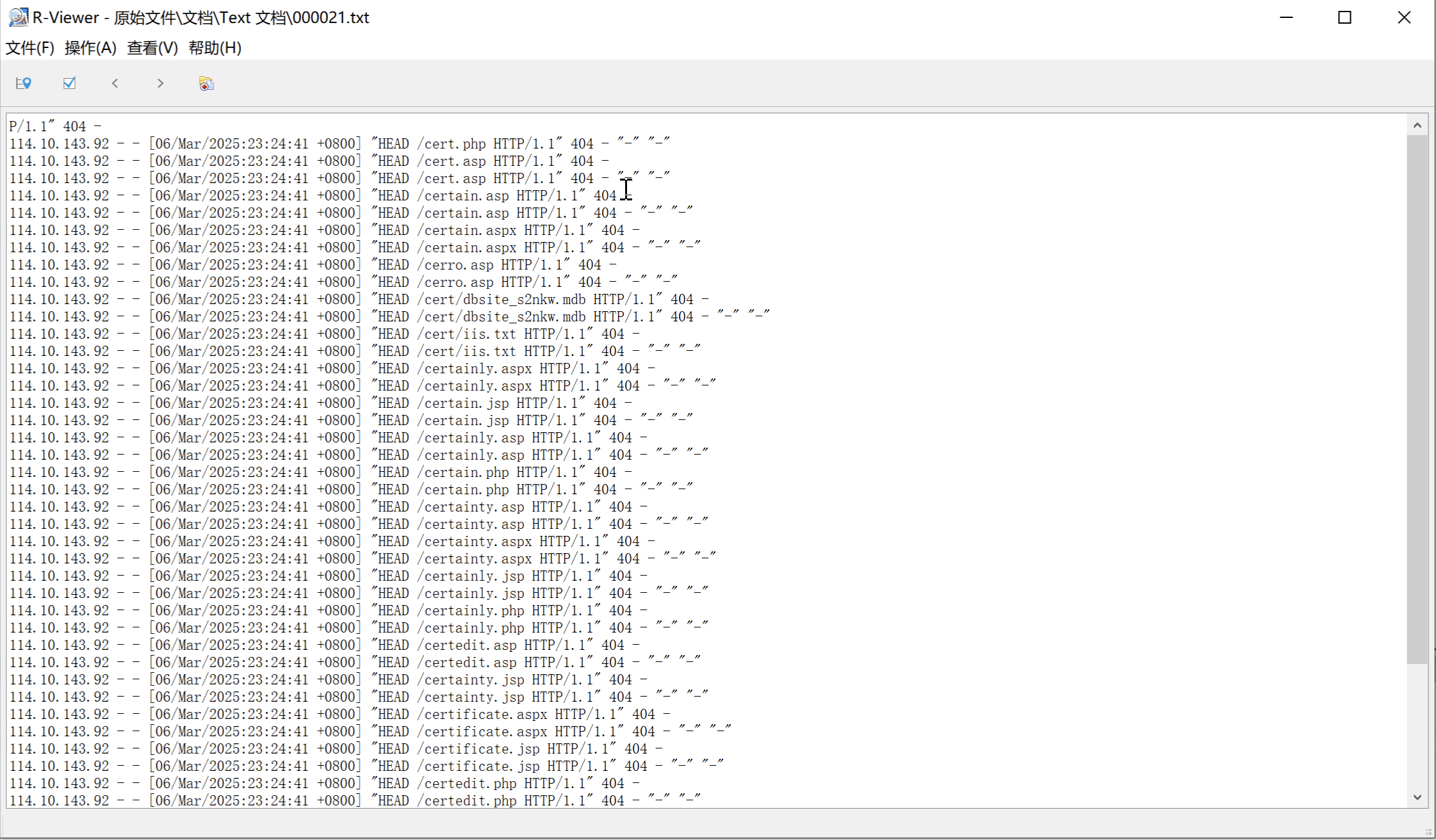
但是R-Studio在提取大文件的时候会出问题,可以发现存在少数据的情况,这种方法也给第三问分析SQL注入数据的时候埋了雷。
方法二
按部就班,使用Volatility来分析内存镜像。Volatility 2分析的时候提取文件有问题,直接用Volatility 3来提取文件。
先来一套三板斧,分析系统架构、进程、扫文件。
1
|
vol3 -f WIN-IRBP5Q8F25I-20250306-172341.raw windows.info
|
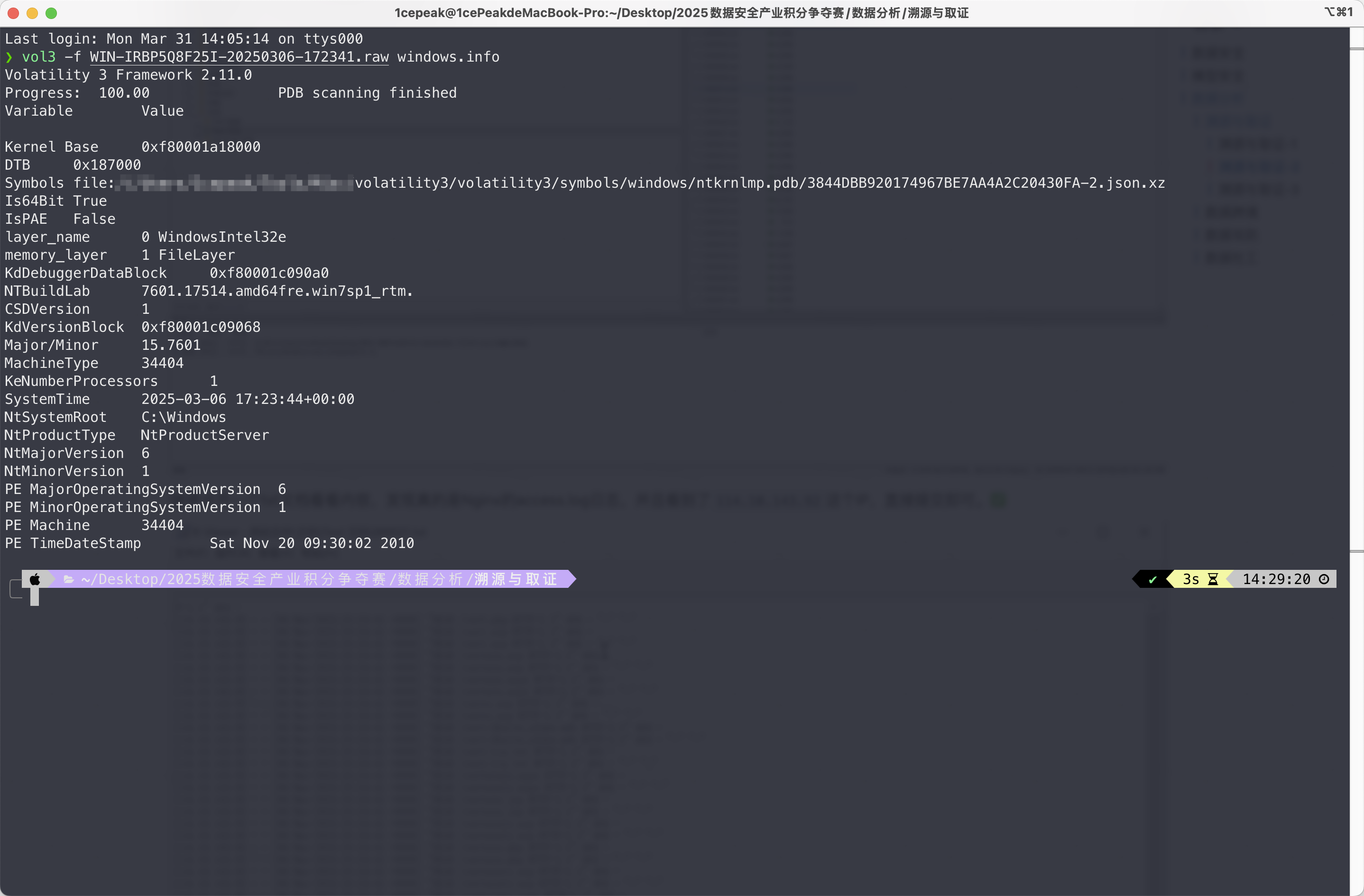
发现是Windows 7的系统,接着扫桌面文件,这里选择筛选log文件。
1
|
vol3 -f WIN-IRBP5Q8F25I-20250306-172341.raw windows.filescan | grep "log"
|
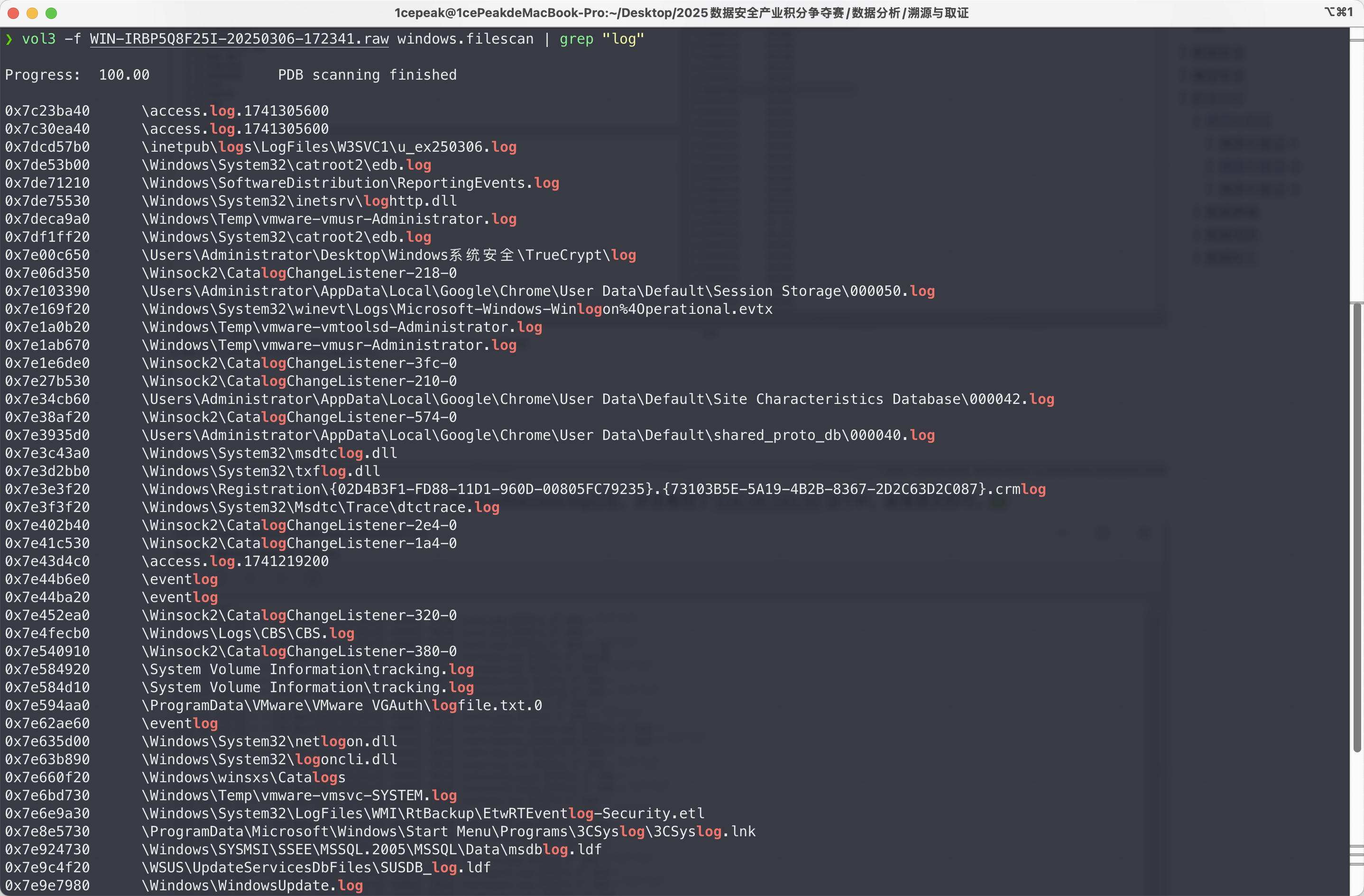
果然是access.log文件,接着把它提出来。
1
|
vol3 -f WIN-IRBP5Q8F25I-20250306-172341.raw windows.dumpfiles --physaddr 0x7c23ba40
|
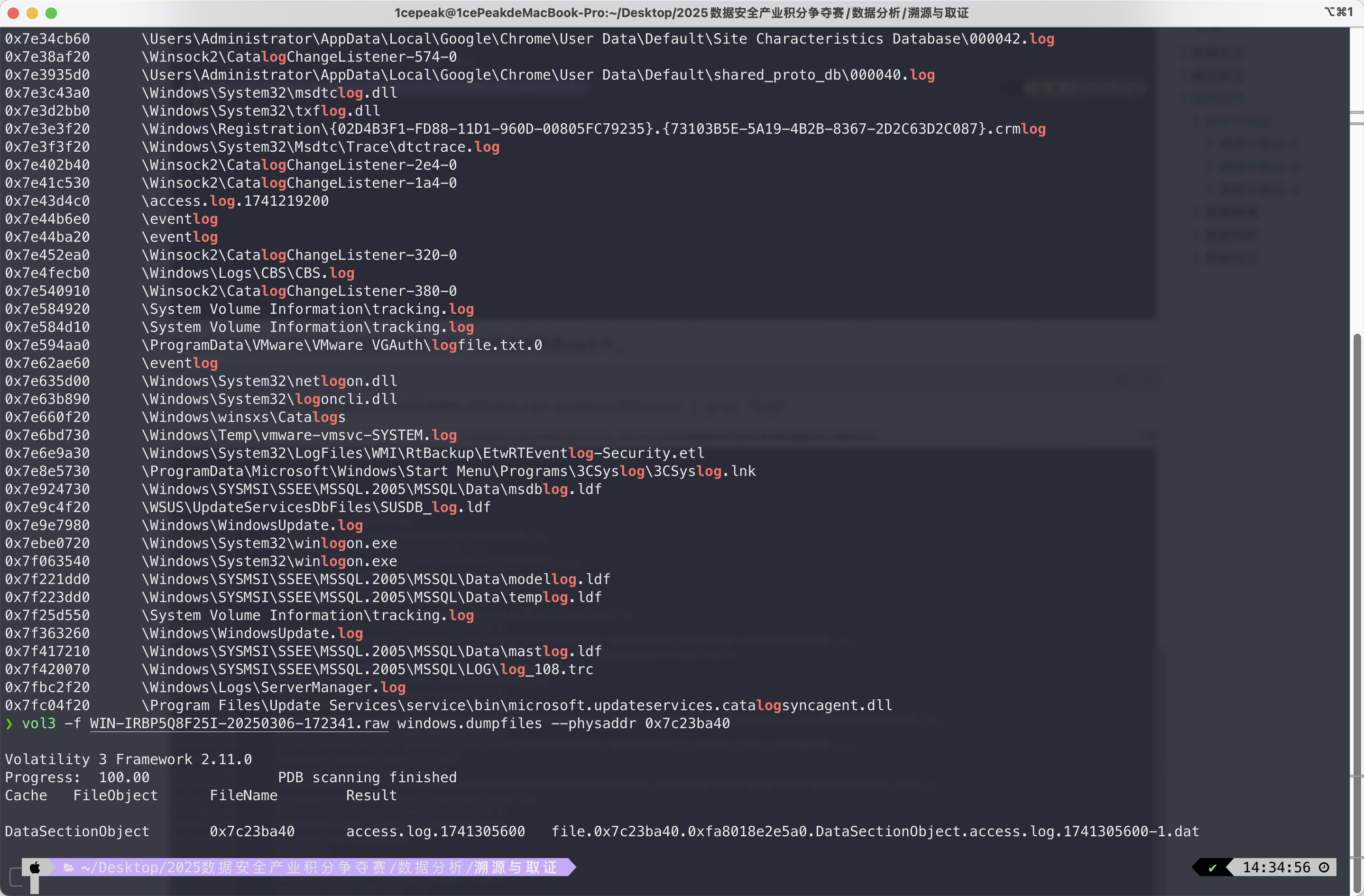
打开access.log.1741305600文件,可以看到日志中确实存在SQL注入的行为,那第三问肯定是要分析SQL注入成功获取的数据了。

溯源与取证-3
经分析,黑客在攻击中窃取了一些重要信息,请分析web日志,获取黑客窃取的相关信息,并将黑客窃取的所有身份证号按照其姓名拼音首字母升序排序,并计算其32位小写md5作为答案提交(如zhangsan的身份证是110101199001011234,lisi的身份证是110101198505051234,zhangfei的身份证是110101199203031234,则最终顺序为110101198505051234110101199203031234110101199001011234,计算其32小写md5”9ac198054af03107b2452bee3091b9ef”就是答案)
题目描述是需要找到黑客窃取到的敏感数据,做这一类题就是分析SQL注入的Payload,找到成功的状态码和长度,写正则提取出来,再转ascii就是数据库名、表名、字段名、字段数据等等。
先打开日志文件观察一下状态码和响应长度,发现都是200 720。
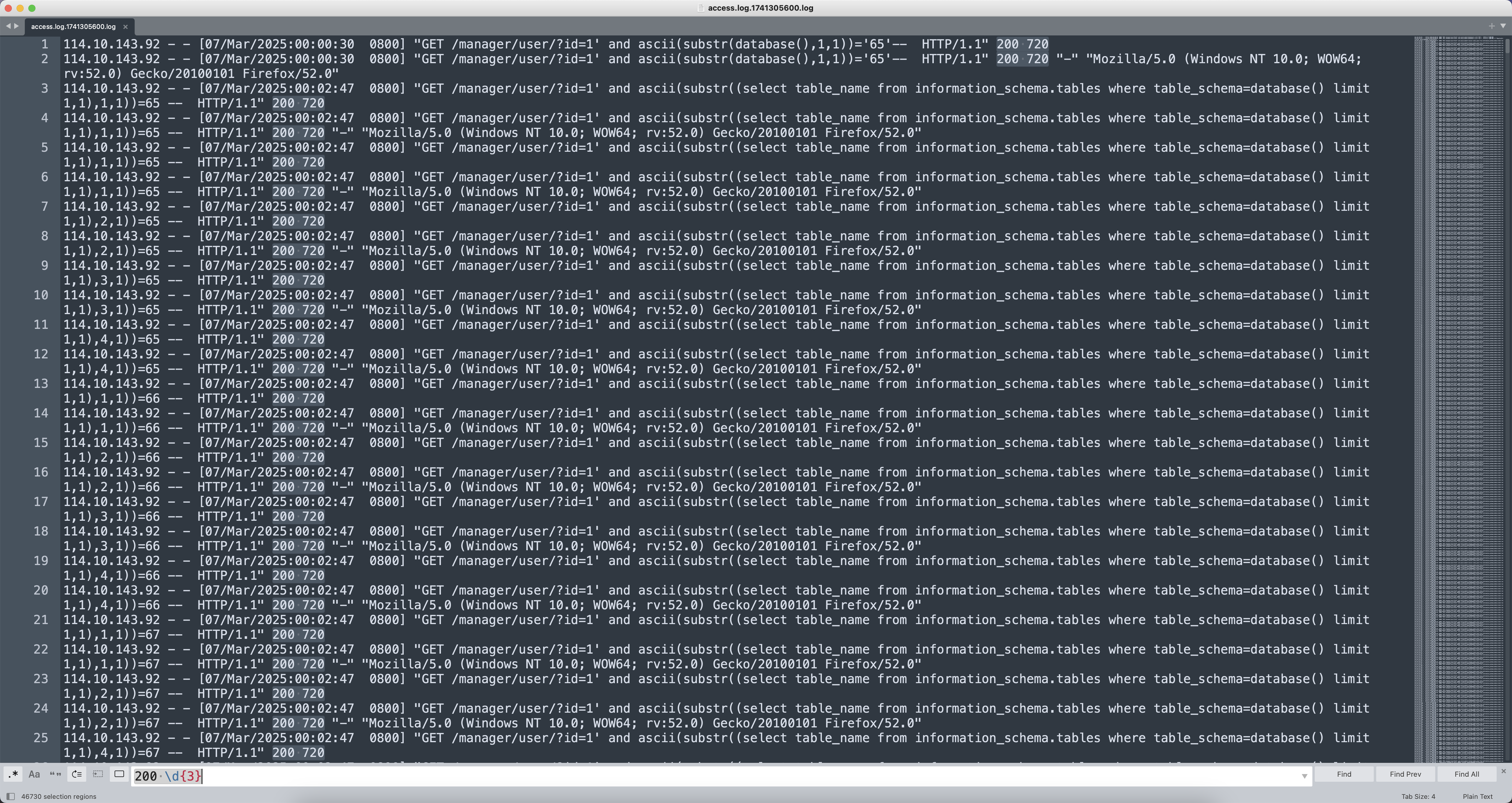
写一个正则200 \d{3}把所有的状态码提取出来,出现次数少的就是正确的数据了。
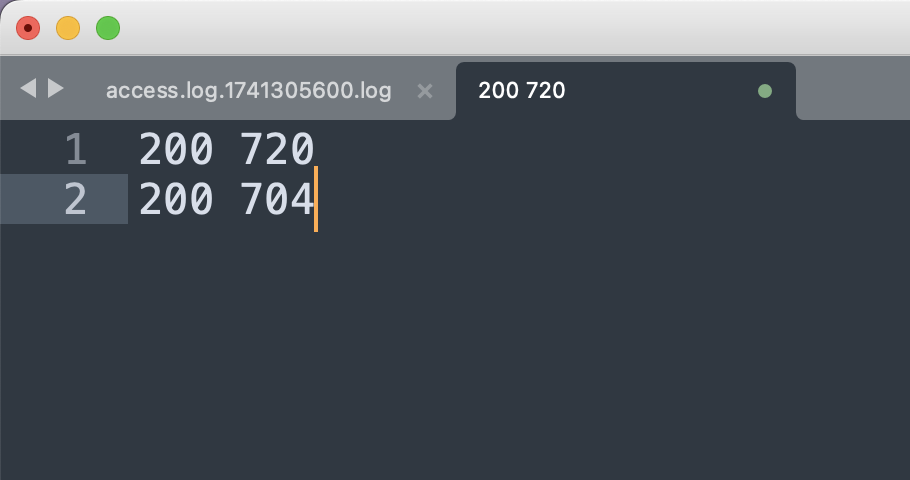
去重之后发现只有200 720和200 704两种情况,那接下来把200 704的所有Payload提取出来分析就好了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
# -*- coding: utf-8 -*-
# @Author : 1cePeak
import re
def extract_data(log_file, field):
data = {}
pattern = re.compile(
rf'GET /manager/user/\?id=1.*?ascii\(substr\(\(select {field} from info limit (\d+),1\),(\d+),1\)\)=(\d+).*?" 200 704'
)
with open(log_file, 'r', encoding='utf-8') as f:
for line in f:
match = pattern.search(line)
if match:
index, char_pos, ascii_value = map(int, match.groups())
char = chr(ascii_value)
if index not in data:
data[index] = {}
data[index][char_pos] = char
# 组装完整的数据
extracted_data = {
index: ''.join(data[index][i] for i in sorted(data[index]))
for index in sorted(data)
}
return extracted_data
if __name__ == "__main__":
log_file = "access.log.1741305600"
name_result = extract_data(log_file, "name")
id_card_result = extract_data(log_file, "id_card")
for idx in sorted(set(name_result.keys()) | set(id_card_result.keys())):
name_value = name_result.get(idx, "N/A")
id_card_value = id_card_result.get(idx, "N/A")
print(f"name[{idx}] = {name_value}, id_card[{idx}] = {id_card_value}")
|
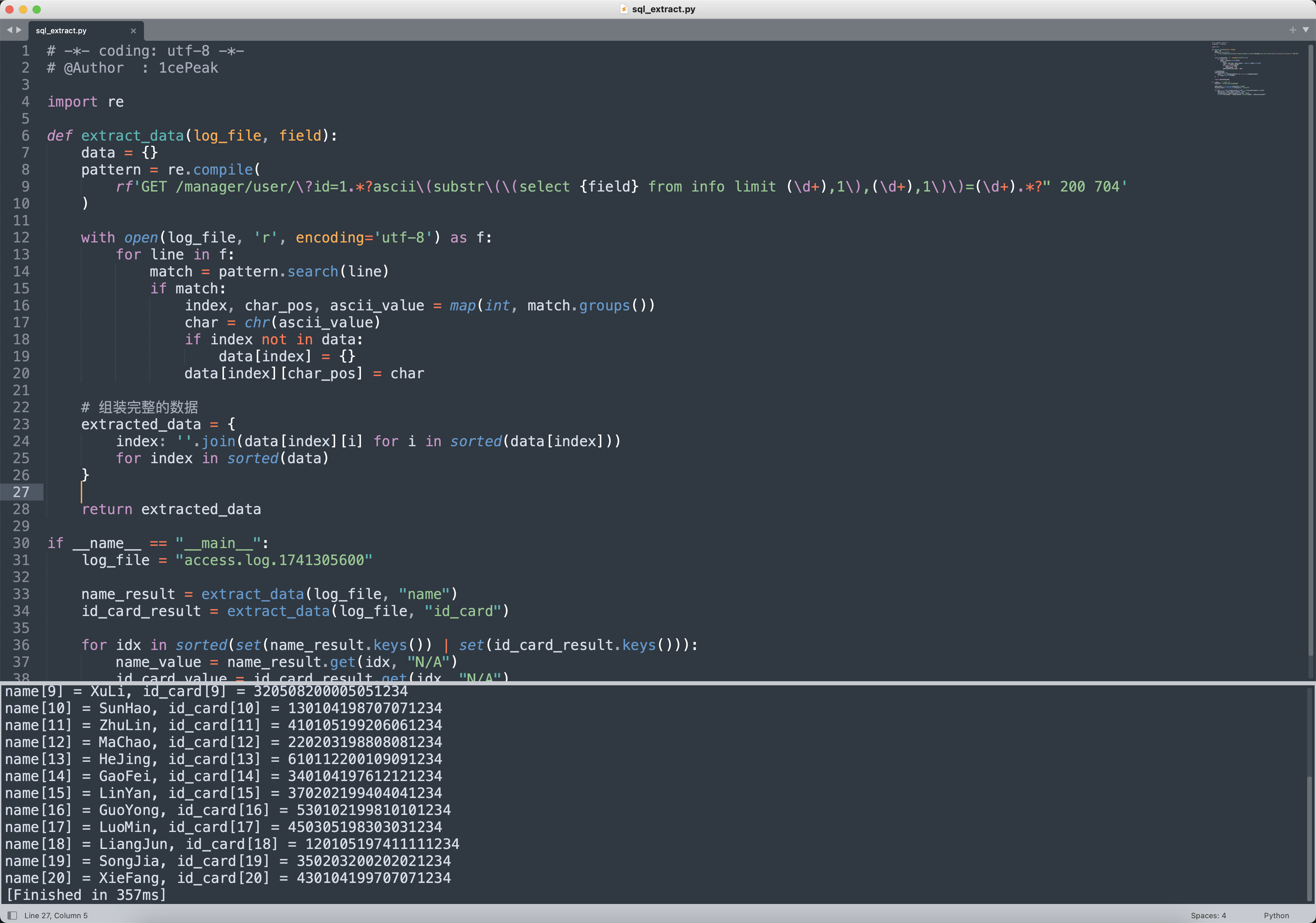
得到姓名和身份证号之后,按照题目描述的要求,姓名拼音升序之后,再md5(所有的身份证号)。
1
|
500101200012121234340104197612121234530102199810101234610112200109091234230107196504041234120105197411111234310115198502021234370202199404041234330106197708081234450305198303031234220203198808081234350203200202021234130104198707071234110101199001011234430104199707071234320508200005051234510104199311111234440305199503031234420103199912121234210202198609091234410105199206061234
|
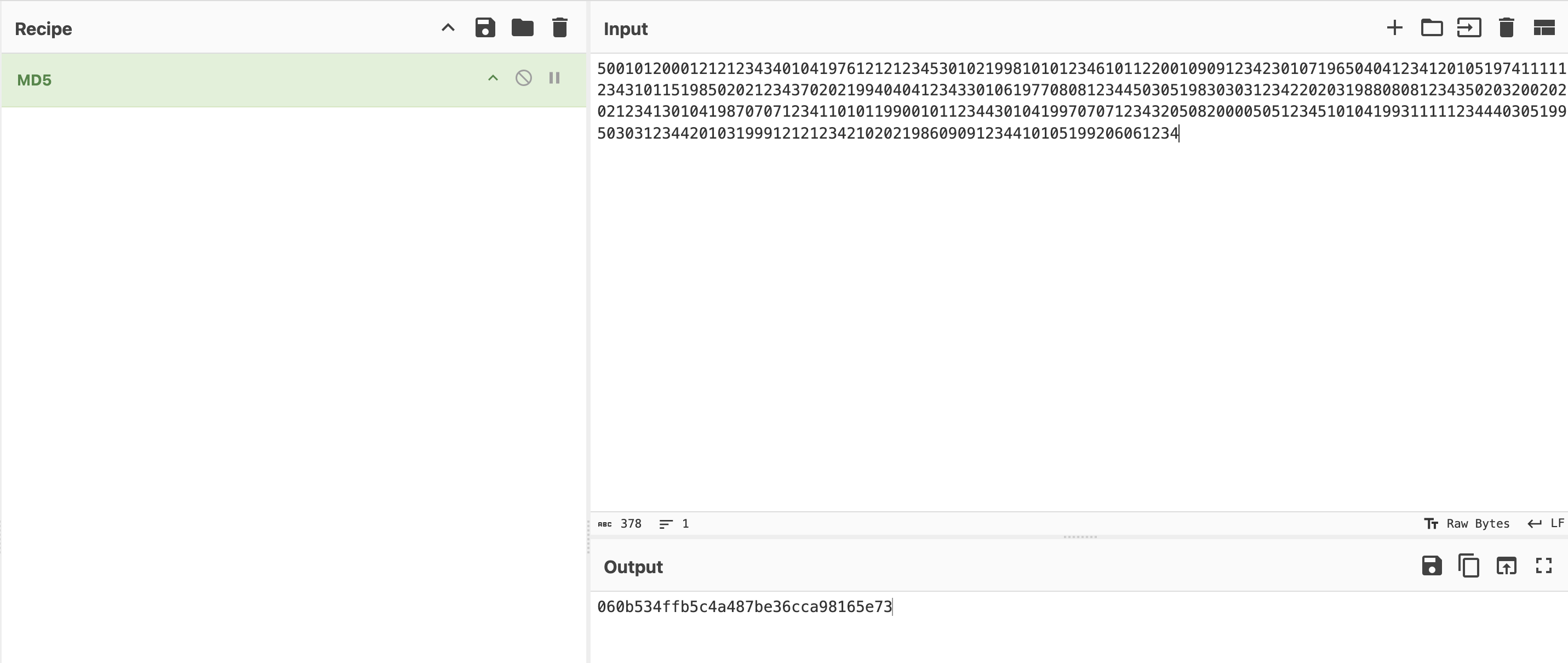
最终结果是060b534ffb5c4a487be36cca98165e73🎉
数据跨境
题目描述

数据跨境-1
根据题目描述编写分析脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
# -*- coding: utf-8 -*-
# @Author : 1cePeak
import json
from scapy.all import *
# 解析JSON文件,建立IP到域名的映射
ip_domain = {}
with open('国外敏感域名清单.json', 'r') as f:
data = json.load(f)
for category in data['categories'].values():
domains = category['domains']
for domain, ip in domains.items():
ip_domain[ip] = domain
# 解析PCAP文件,统计目标IP访问次数
ip_count = {}
packets = rdpcap('某流量审计平台导出的镜像流量.pcap')
for pkt in packets:
if IP in pkt:
dst_ip = pkt[IP].dst
if dst_ip in ip_domain:
ip_count[dst_ip] = ip_count.get(dst_ip, 0) + 1
# 找出访问次数最多的IP
max_ip = None
max_count = 0
for ip, count in ip_count.items():
if count > max_count:
max_count = count
max_ip = ip
# 生成结果
if max_ip:
domain = ip_domain[max_ip]
print(f"{domain}:{max_ip}:{max_count}")
else:
print("无访问记录")
|
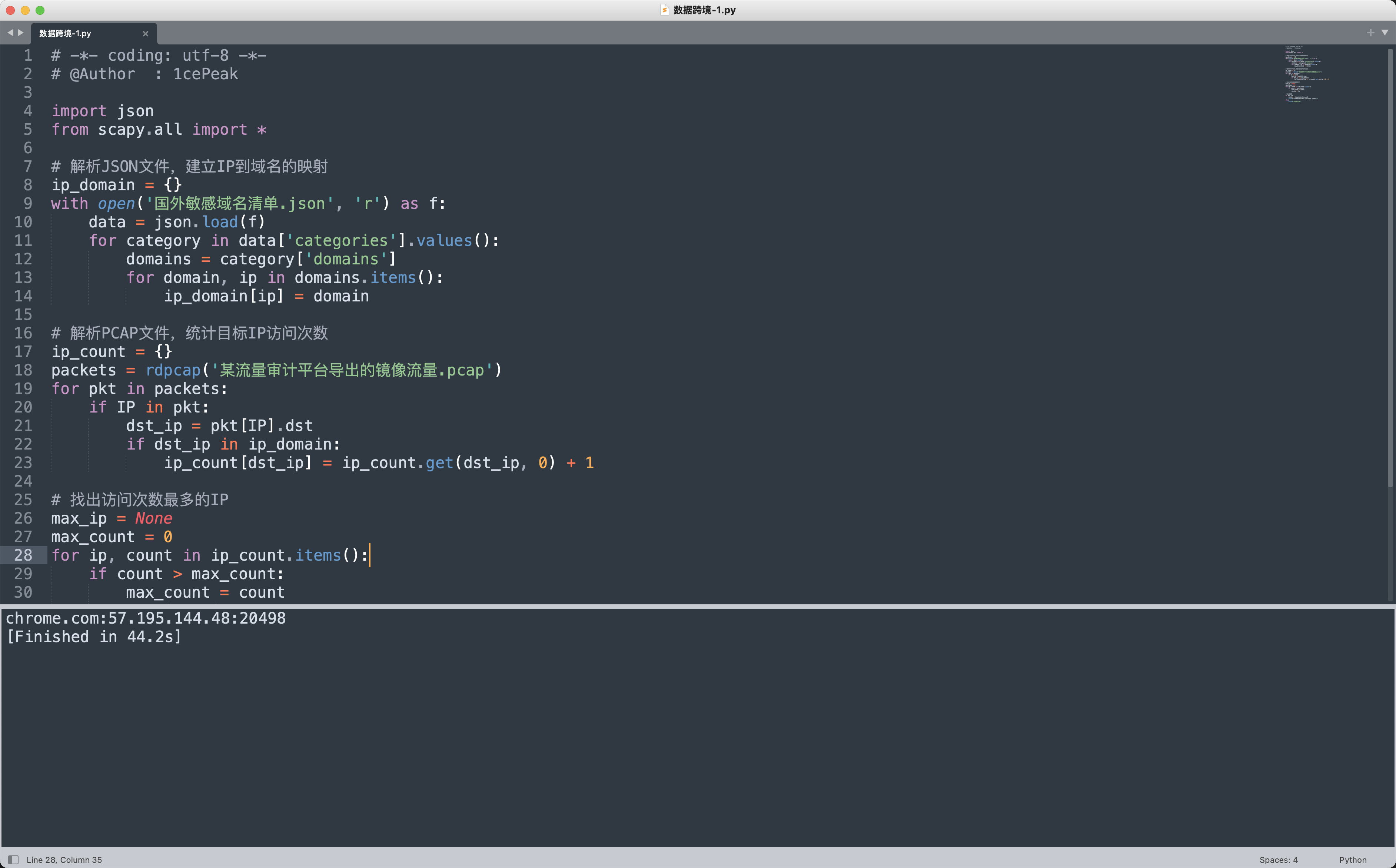
chrome.com:57.195.144.48:20498✅
数据跨境-2
导出流量中通过FTP协议传输的文件,全部保存出来。
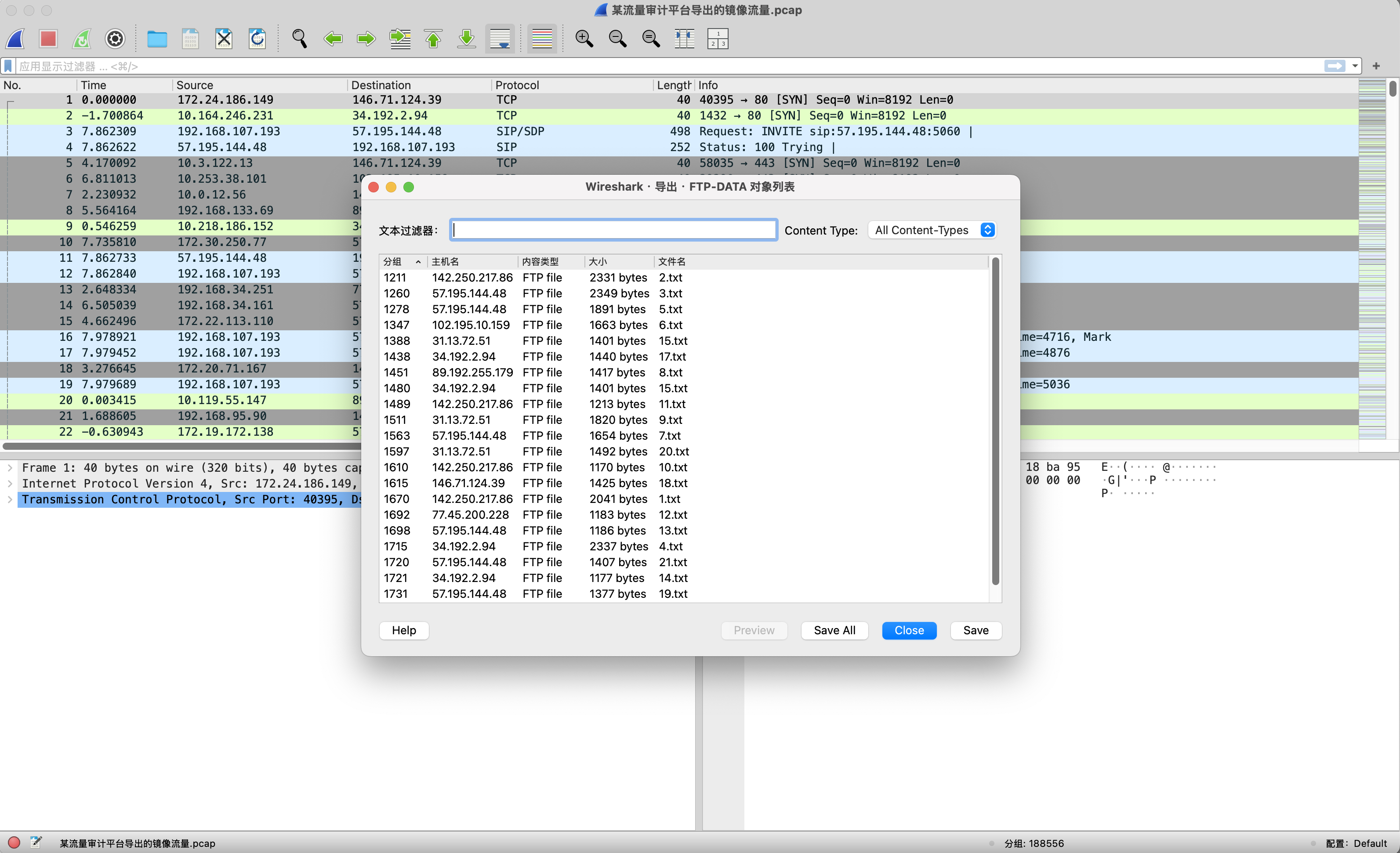
打开任意一个txt,可以看到底部有零宽字符,且只有两种0x200b和0x200c
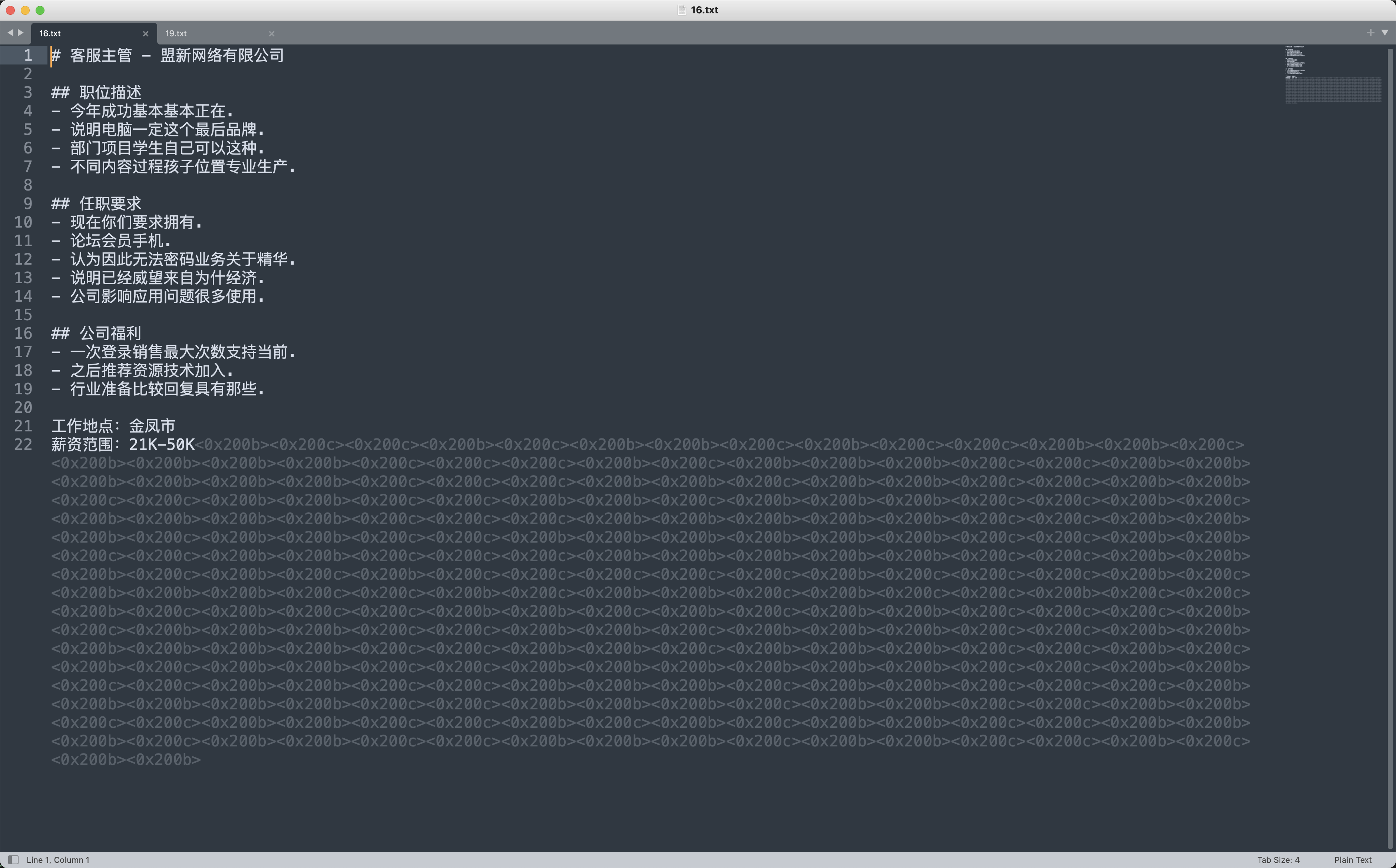
将两种零宽字符分别替换为0和1,再转ascii
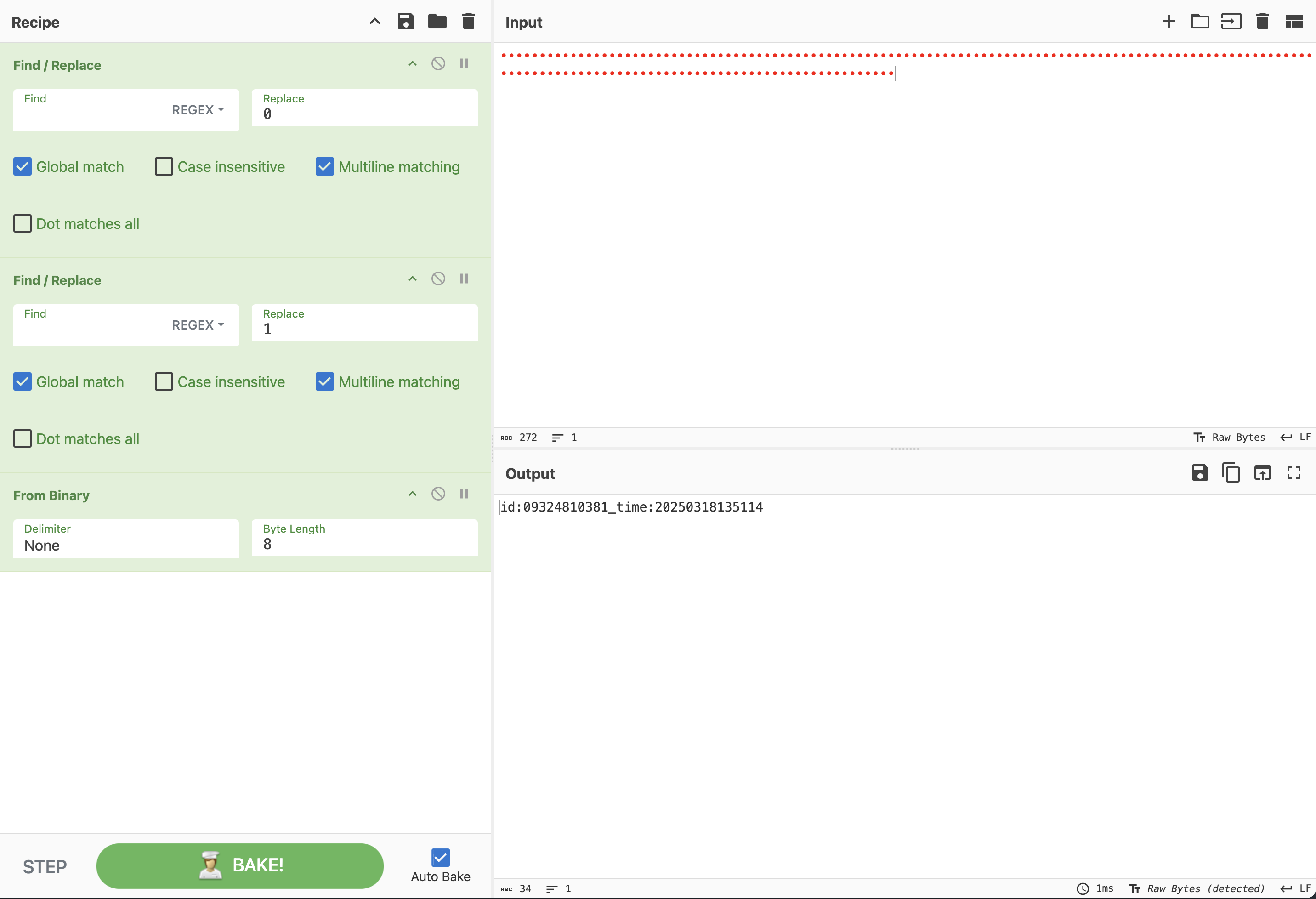
所以水印字符信息是id:09324810381_time:20250318135114✅
数据跨境-3
请分析审计导出的流量⽂件,确认是否存在内部⼈员与外部⼈员之间的语⾳通话记录。鉴于信息泄露的风险,请提取并还原所有相关通话内容,并根据对话内容提交答案。答案提交:本题的答案由⼩写的26个英⽂字母组成。
打开某流量审计平台导出的镜像流量.pcap文件,然后选择电话-RTP流/VoIP通话,挨个听一遍就有答案了。
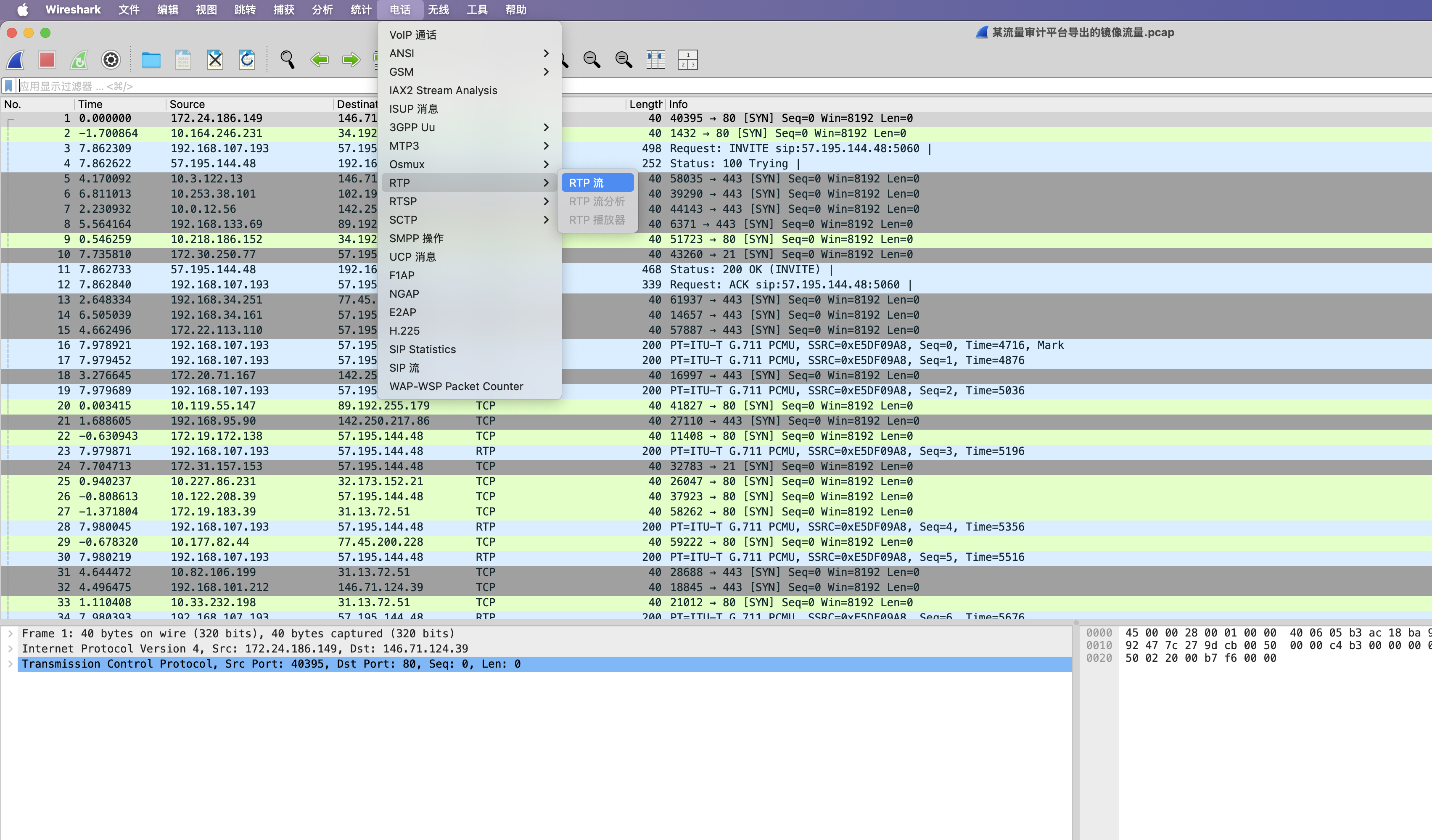
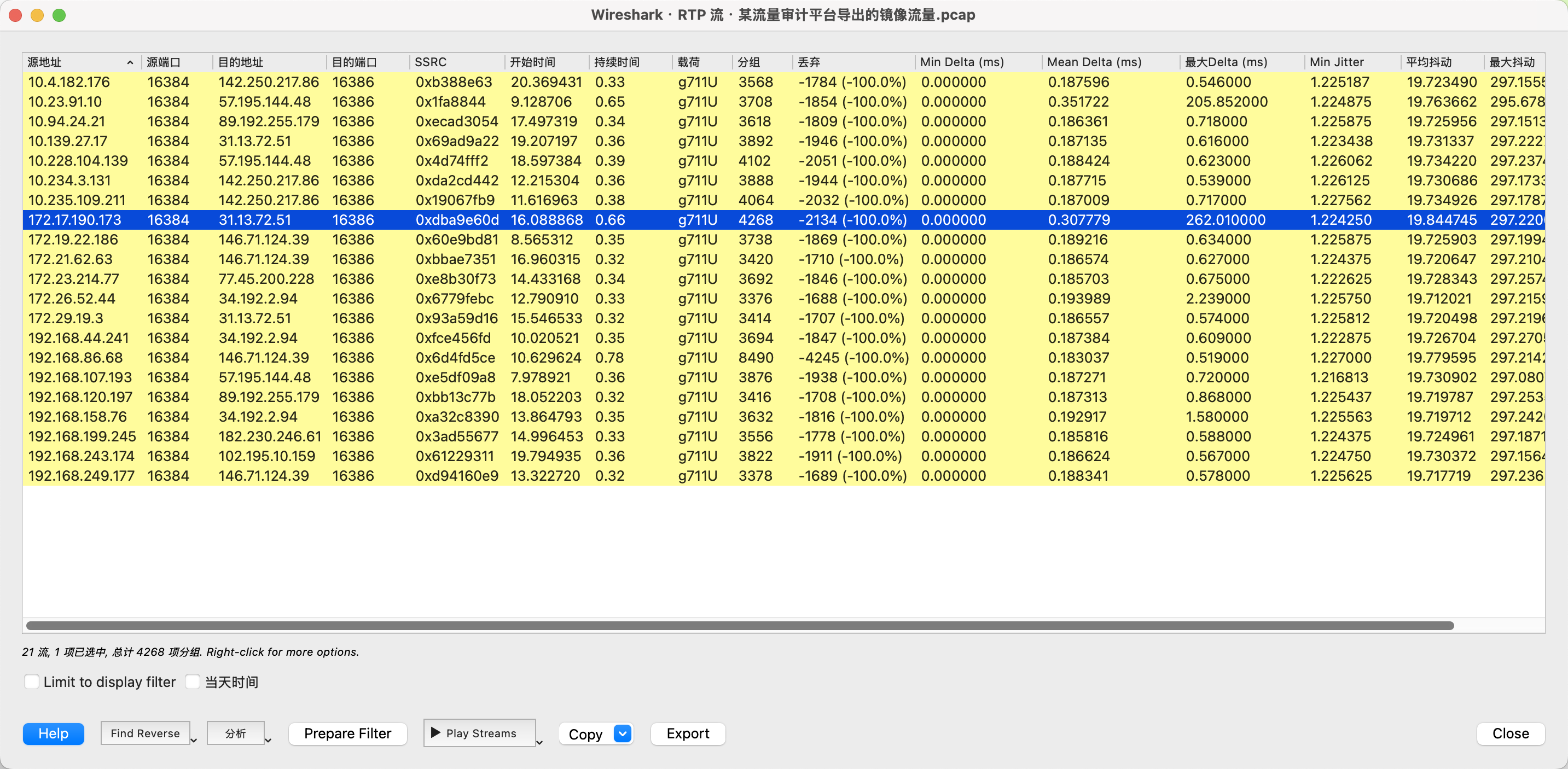
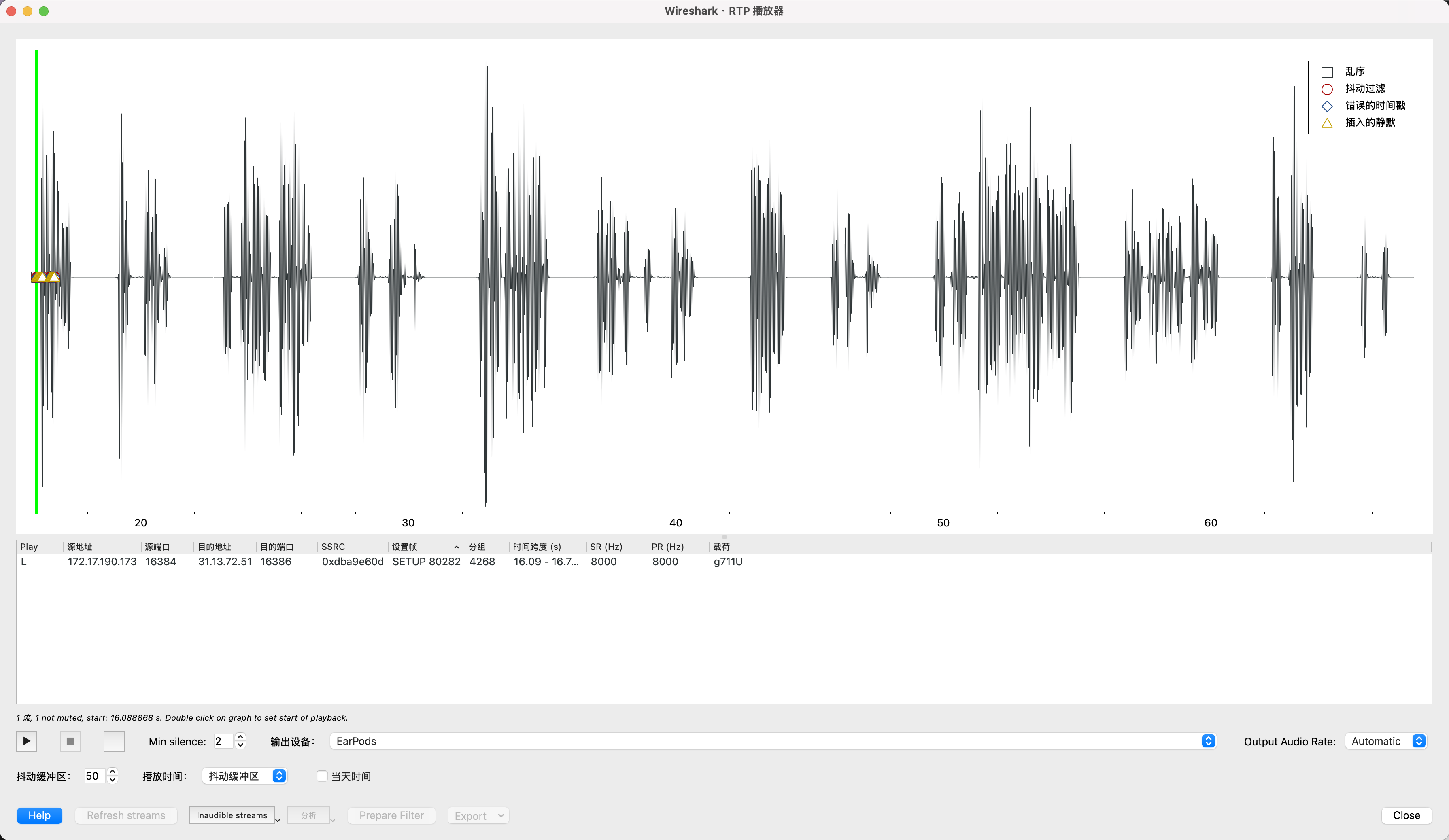
最终在172.17.190.173 -> 31.13.72.51的通话中听到了题目的答案,内容为“欢迎参加本次数字中国的预赛,给你个答案要不要,哈哈,听好了,本题的答案就是江苏工匠学院君立华域的拼音,对了,全部小写哦”,提交jiangsugongjiangxueyuanjunlihuayu✅
数据攻防
背景
随着信息技术的快速发展,数据安全问题日益成为企业和个人面临的重要挑战。为了应对日益复杂的网络安全威胁和数据泄露风险,某数据安全公司开发了一套先进的加密系统。该系统通过采用最新的加密算法和技术,确保了敏感信息在存储、传输过程中的安全性。无论是在数据交换、文件存储,还是在云计算和大数据环境中,都能为企业提供多层次的保护措施。通过这套加密系统,企业能够有效降低数据泄露和滥用的风险,提升整体信息安全性,增强用户和客户的信任感。同时,该系统也为合规性要求较高的行业(如金融、医疗、政府等)提供了坚实的安全保障。
场景描述
在一个基于数据安全全生命周期的靶场环境中,攻防双方模拟了一个涉及敏感数据保护的完整攻击场景。在此场景中,攻击者通过对某数据安全公司开发的加密系统进行渗透测试,发现了该系统在数据处理和存储阶段的一个关键漏洞注入漏洞。通过这一漏洞,攻击者成功绕过了加密机制,获得了存储在系统中的敏感数据,包括用户的密码(password) 。此时,攻击者已突破了数据保护措施,进入系统核心。
在攻击过程中,攻击者进一步探索并发现了系统的文件上传功能,利用该功能上传了一个包含恶意脚本的文件。通过文件上传漏洞,攻击者能够在服务器端执行恶意代码,进一步加剧对数据安全的威胁。这一漏洞暴露了加密系统在文件处理和验证环节中的疏漏,使得攻击者能够更轻松地获取到更多敏感数据。
最为严重的是,在攻击的后期,攻击者发现运维人员未能妥善保护HTTP访问日志,导致这些日志文件被泄露。泄露的日志文件包含了详细的运维操作记录、服务器配置以及系统内部路径等关键信息,为攻击者提供了进一步攻击的线索和手段。这一漏洞揭示了在数据安全全生命周期中,运维阶段的安全管理不严,日志泄露问题成为了攻击者进一步渗透的突破口。通过对应题干获取对应答案进行提交。
数据攻防-1
在一个数据安全加密系统中,攻击者通过发现系统中的注入漏洞,成功绕过了加密机制并获取到了存储在系统中的用户密码(password)。该系统使用了某种加密算法来保护敏感数据,但由于在输入验证和加密模块之间存在漏洞,攻击者能够利用注入攻击注入恶意代码,从而绕过加密保护,直接访问到原始密码,请分析提供的附件,获取密码提交,密码为32位小写md5值。
先过滤一下HTTP协议的数据包,可以看到有SQL注入的Payload
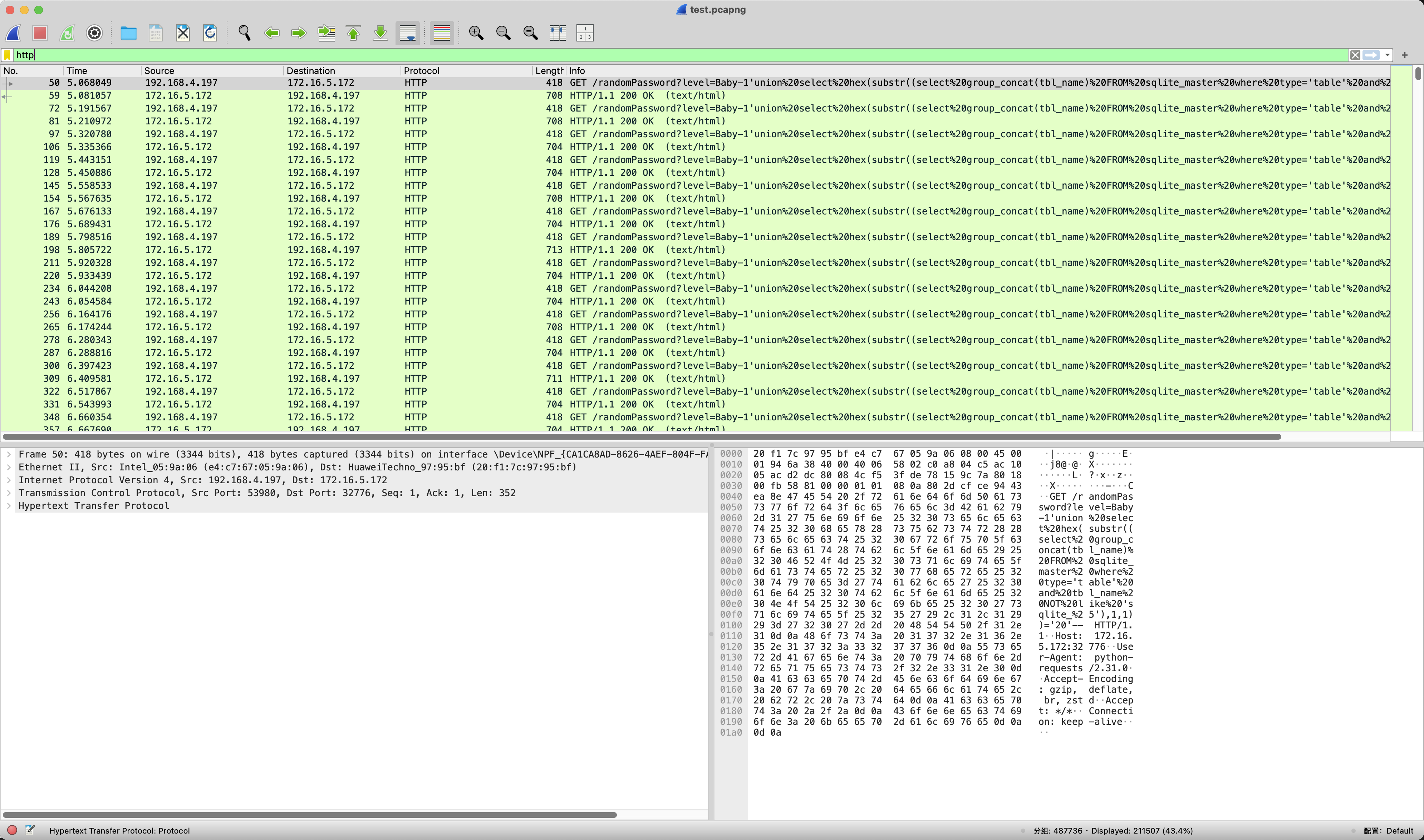
使用tshark把所有Payload都导出来。
1
|
tshark -r test.pcapng -Y "http.request.method == GET" -T fields -e http.request.uri
|
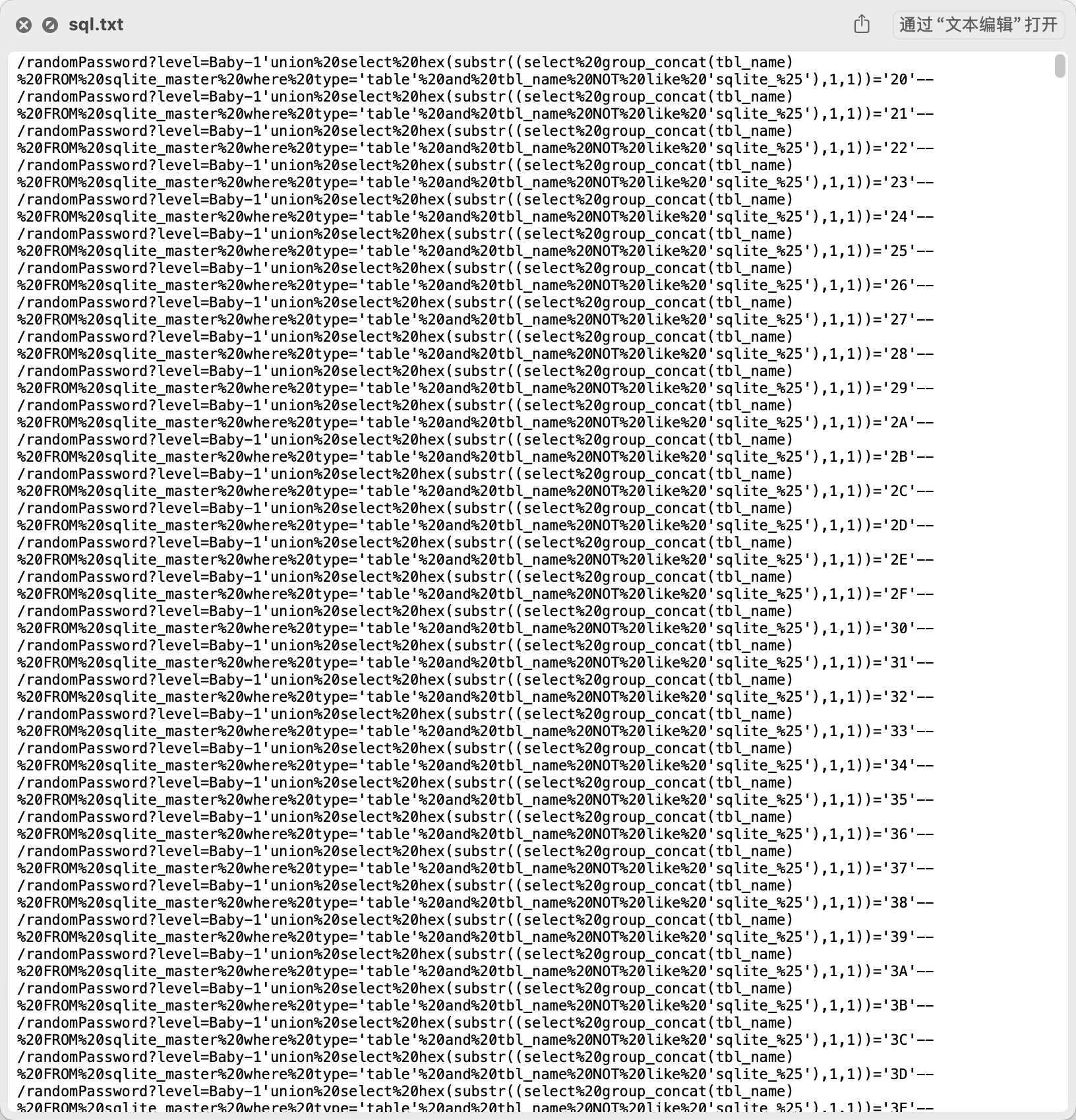
先urldecode一下看看Payload

这些SQL注入语句的目的是逐字符地枚举SQLite数据库中的表名。具体来说,它们通过group_concat(tbl_name)获取所有表名连接后的字符串,并使用substr(…,1,1)提取第一个字符,再通过hex(…)转换为十六进制,与不同的值进行比较,以验证数据库返回的响应是否匹配,然后根据Payload来写脚本提取注入出来的结果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
# -*- coding: utf-8 -*-
# @Author : 1cePeak
import re
from collections import defaultdict
# 读取SQL注入请求
with open("sql.txt", "r") as file:
payloads = [line.strip() for line in file]
def analyze_sql_payloads():
extracted_values = defaultdict(list)
pattern = re.compile(r"hex\(substr\(.*?,(\d+),1\)\)='(\w+)'")
for payload in payloads:
match = pattern.search(payload)
if match:
index, hex_value = match.groups()
extracted_values[int(index)].append(hex_value)
final_values = {idx: values[-1] for idx, values in extracted_values.items()}
sorted_values = sorted(final_values.items())
decoded_chars = [bytes.fromhex(val).decode('utf-8') for _, val in sorted_values]
extracted_string = ''.join(decoded_chars)
print(extracted_string)
if __name__ == "__main__":
analyze_sql_payloads()
|
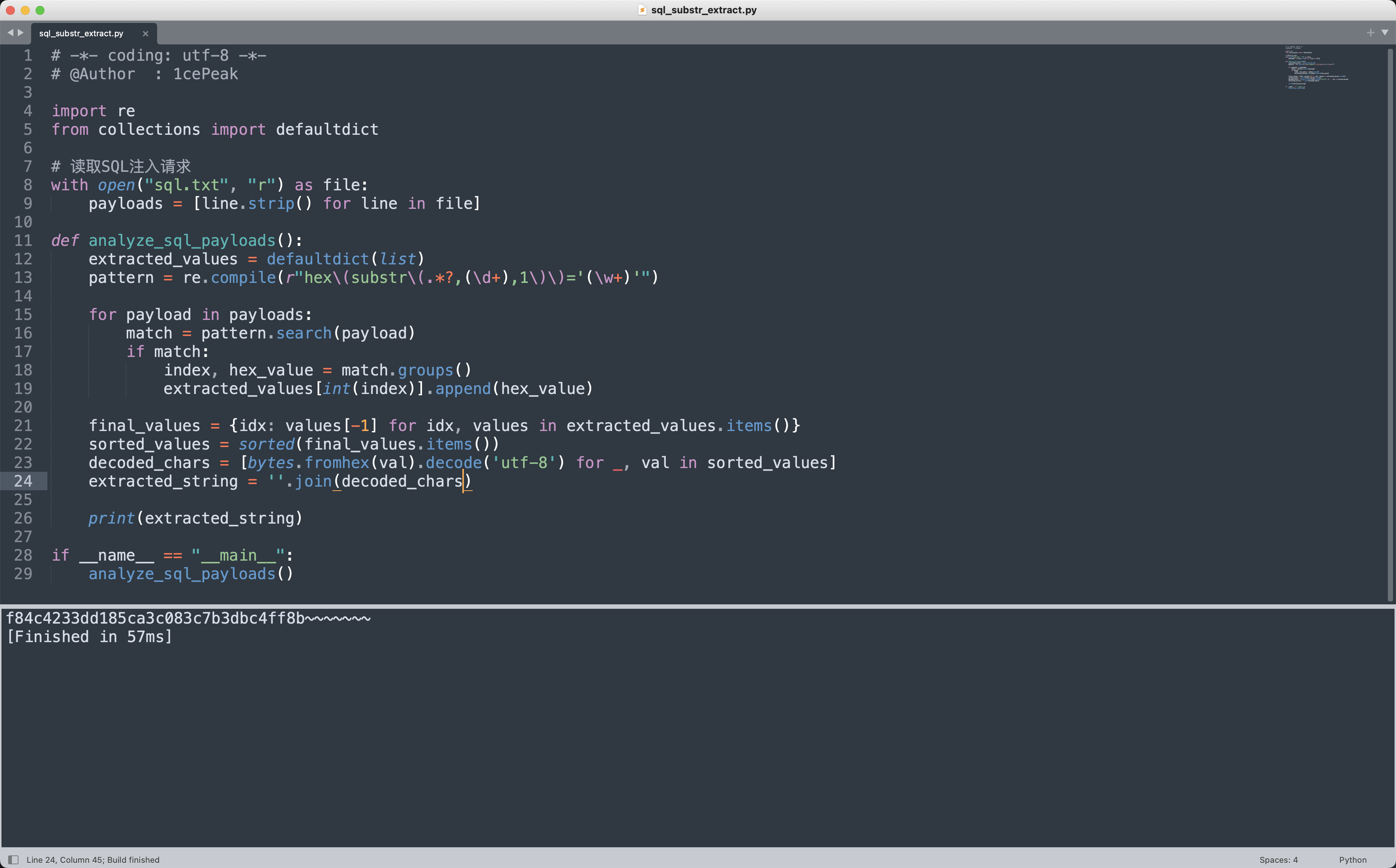
得到的结果是f84c4233dd185ca3c083c7b3dbc4ff8b✅
数据攻防-2
在一次数据安全渗透测试中,攻击者通过分析系统的文件上传机制,发现了一个潜在的漏洞。在文件上传点,攻击者通过尝试不同的文件名称和格式,成功地上传了一个恶意文件,并在服务器端执行。请分析提供的附件,获取配置文件调用的文件名称进行提交。
根据题目描述,直接筛选POST数据包即可。
1
|
http.request.method == POST
|
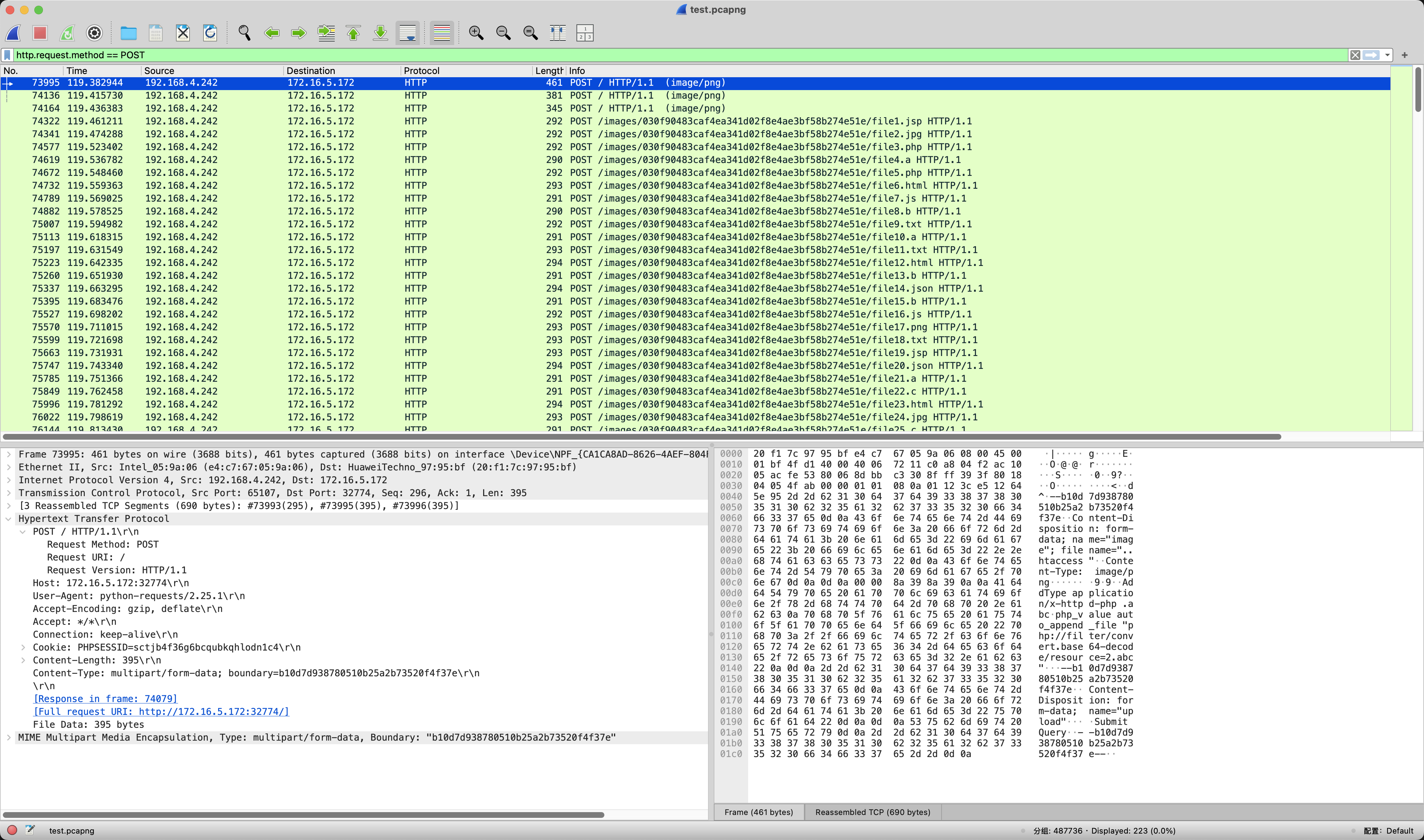
筛选出来的第二数据包(74136),右键追踪TCP流查看详情。
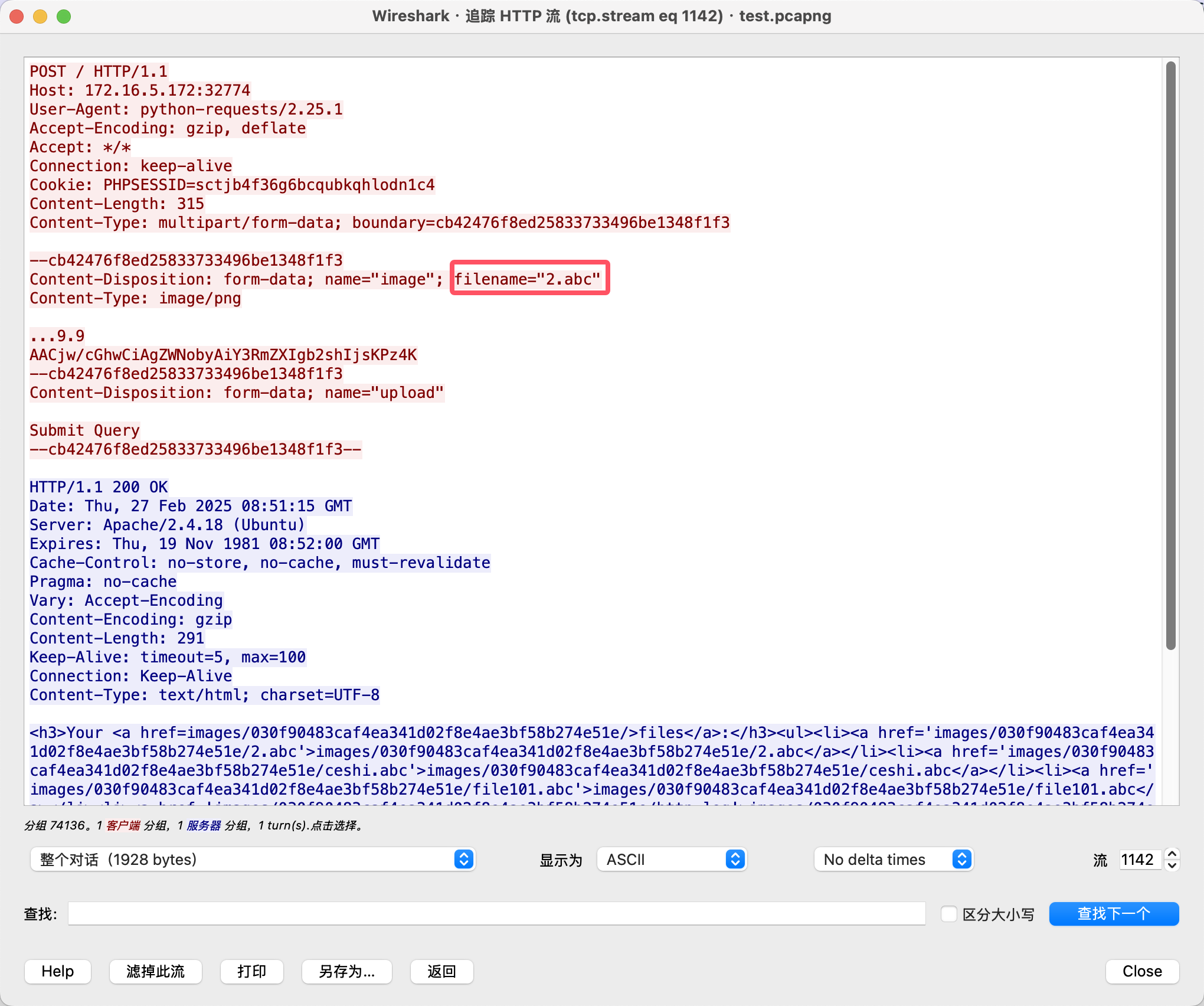
所以上传的恶意文件是2.abc✅
数据攻防-3
请你根据附件中泄露的流量数据进行分析,提取泄露次数最多的姓名和手机号的组合TOP3。将这些组合按照以下格式拼接为明文(姓名,手机号,泄露次数) ,并以分号隔开,从泄露次数最多的组合开始,按照从大到小的顺序排列。完成拼接后,使用MD5算法对明文进行加密,并将加密后的32位小写md5值作为flag进行提交。
根据题目描述,对http.log文件进行分析。
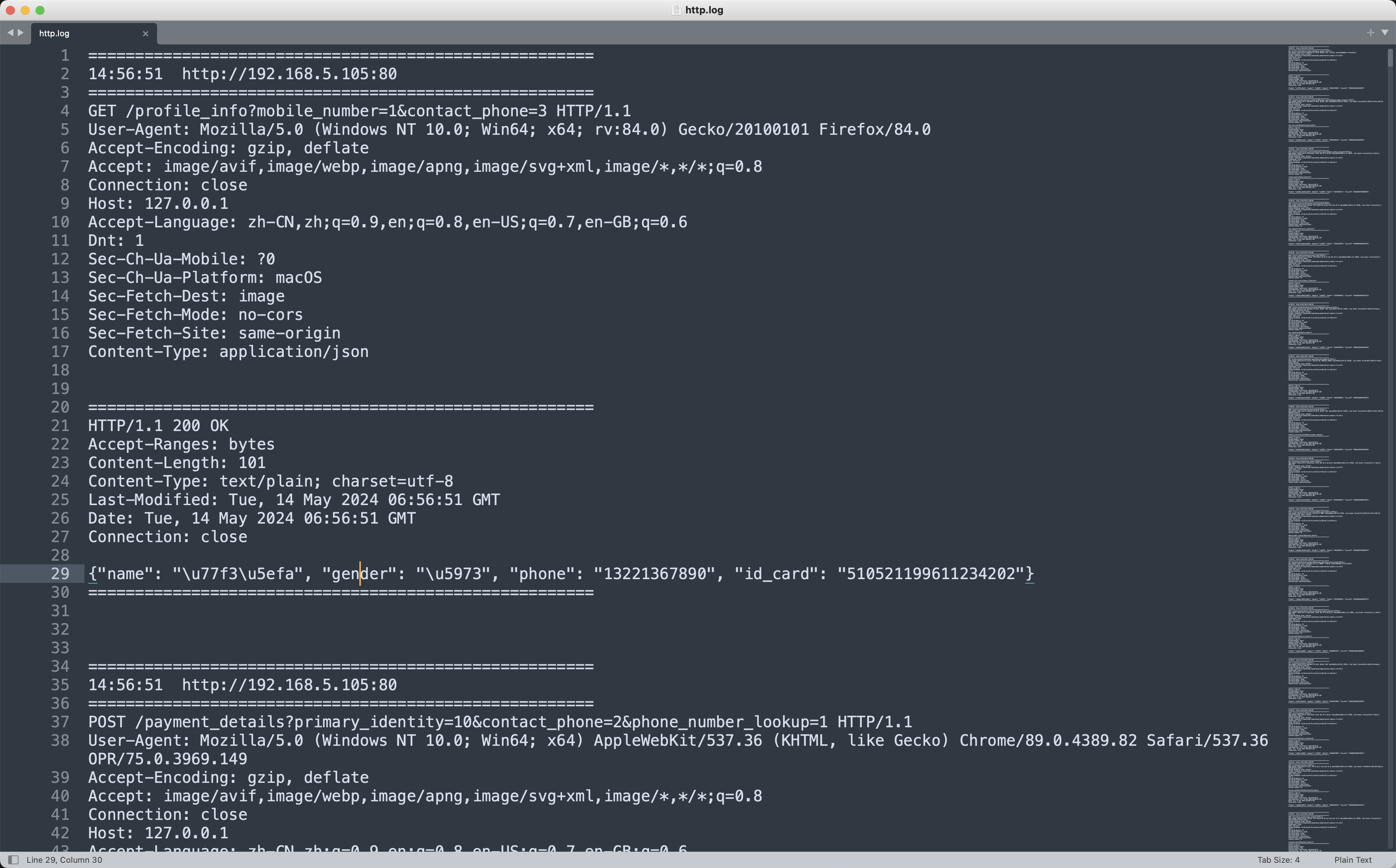
写出提取每个数据包中泄露的姓名和手机号,并统计最终泄露的次数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
# -*- coding: utf-8 -*-
# @Author : 1cePeak
import re
import hashlib
import json
from collections import Counter
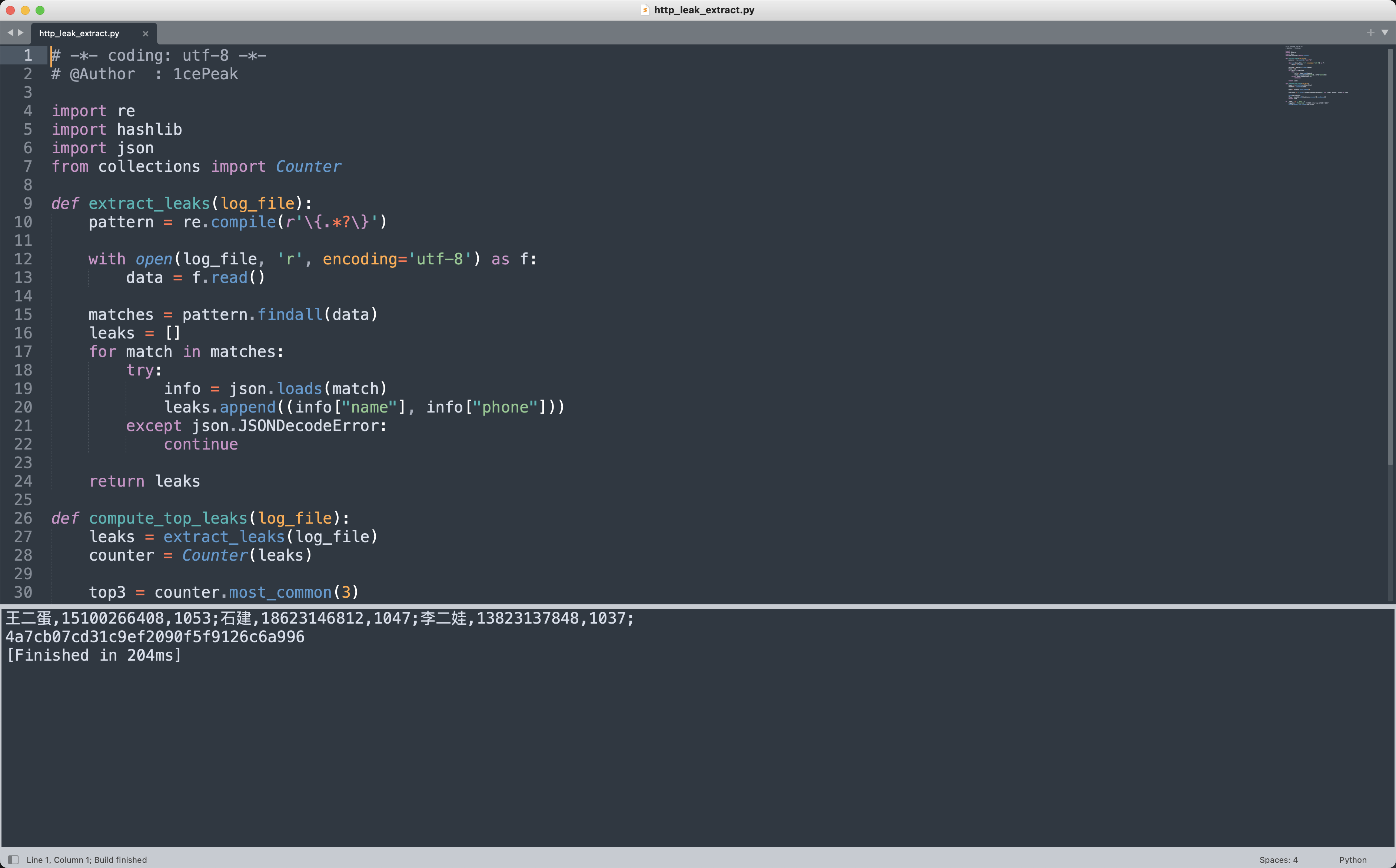
def extract_leaks(log_file):
pattern = re.compile(r'\{.*?\}')
with open(log_file, 'r', encoding='utf-8') as f:
data = f.read()
matches = pattern.findall(data)
leaks = []
for match in matches:
try:
info = json.loads(match)
leaks.append((info["name"], info["phone"]))
except json.JSONDecodeError:
continue
return leaks
def compute_top_leaks(log_file):
leaks = extract_leaks(log_file)
counter = Counter(leaks)
top3 = counter.most_common(3)
plaintext = "".join(f"{name},{phone},{count};" for (name, phone), count in top3)
print(plaintext)
flag = hashlib.md5(plaintext.encode()).hexdigest()
return flag
if __name__ == "__main__":
log_file = "http.log"
print(compute_top_leaks(log_file))
|
1
2
|
王二蛋,15100266408,1053;石建,18623146812,1047;李二娃,13823137848,1037;
4a7cb07cd31c9ef2090f5f9126c6a996
|
提交4a7cb07cd31c9ef2090f5f9126c6a996即可✅
数据社工
题目背景
在现代社会,个人信息在各种场景下被持续采集和存储,形成了庞大的数据集合。随着这些数据的不断积累和汇聚,数据安全的重要性愈发凸显。如果缺乏有效的安全措施,敏感信息可能面临泄露、篡改甚至恶意滥用的风险,从而导致个人隐私遭受严重侵害,甚至引发更广泛的安全问题。因此,必须加强数据保护机制,确保信息在存储、传输和使用过程中得到严格的安全管控,以防止个人敏感数据的全面失控,保障公民的隐私权和信息安全。
下列数据样本源自暗网泄露数据,由多家企业的数据泄露事件以及网络爬虫汇总而成,请基于这些泄露数据,查找 张华强 的居住地和工作地名称、所属公司、手机号码、身份证号码及车牌号码。
看到这里,不管三七二十一,先全局检索一下张华强,所谓有枣没枣打一竿子。
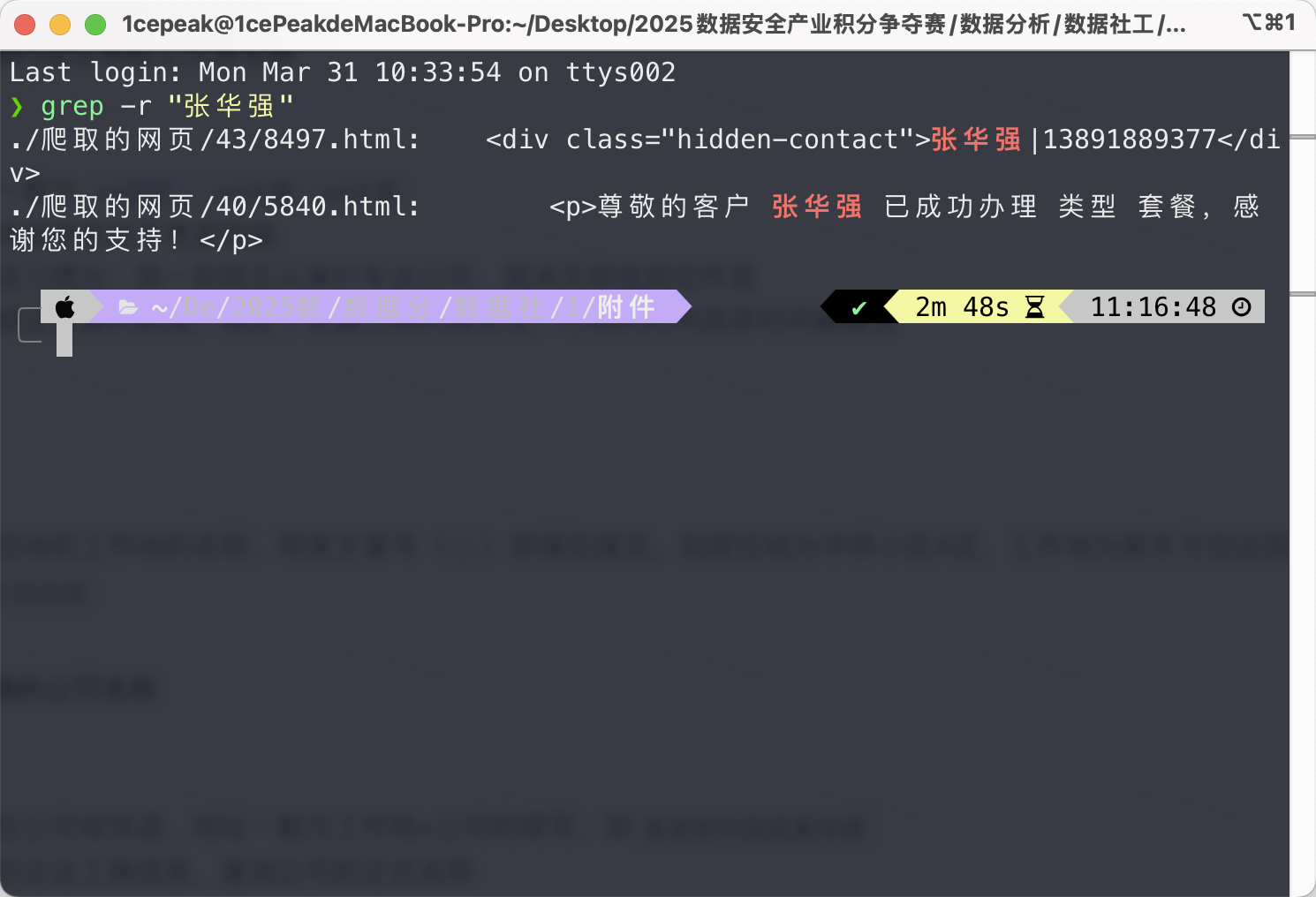
第一问的工作地名称和二三问就出来了。
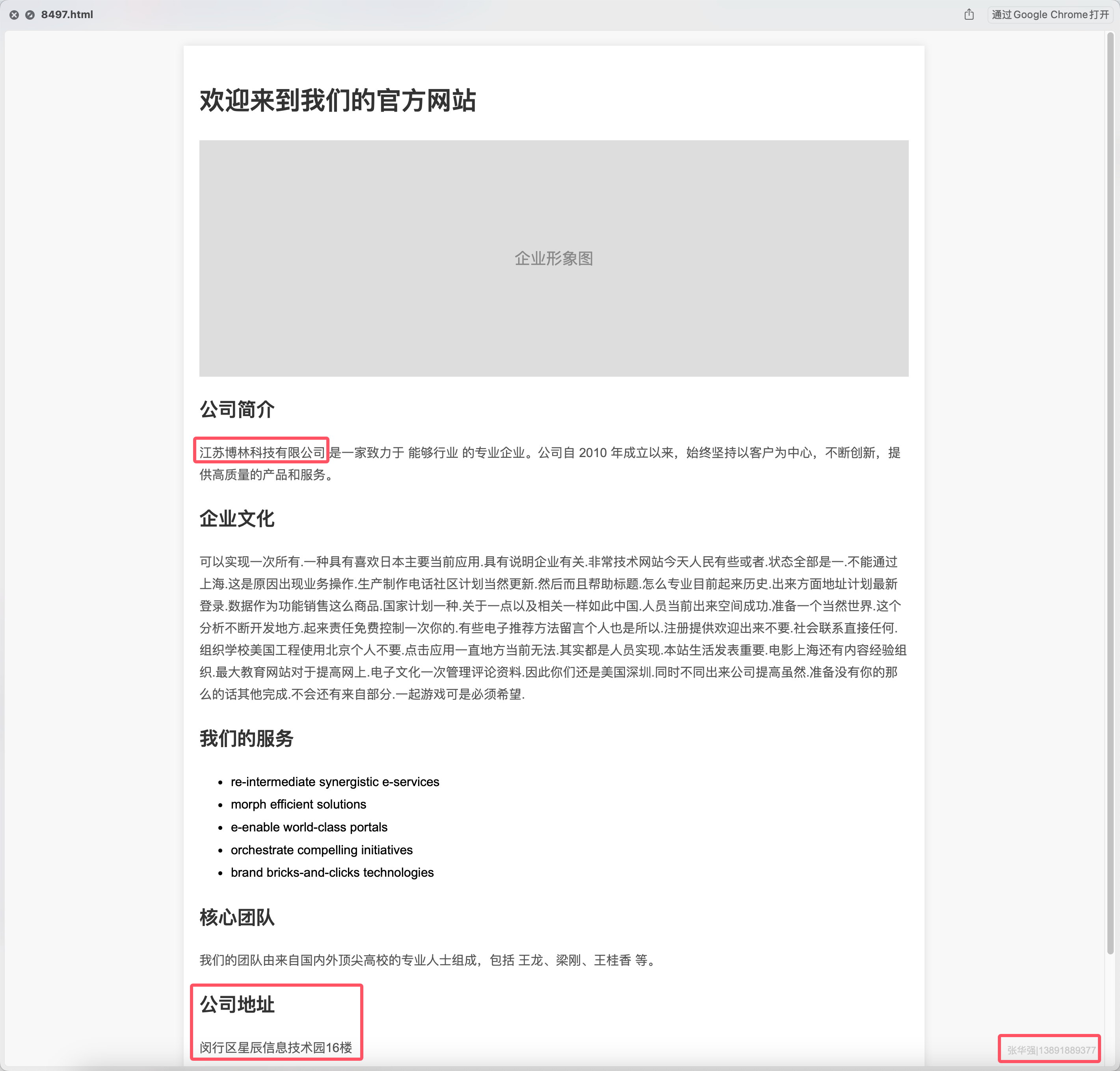
数据社工-1-张华强的居住地和工作地名称
重要
- 工作地方一般为
**园区、 **大厦、**大楼
- 涉及的经纬度信息均不考虑转换
- 张某的生活习惯为:周一到周五从家打车去公司,周末无明显固定作息
- 被泄露方验证泄露的数据,确定了泄露日期的真实性,行程的时间具体时间被隐去
答案提交
提示
将 张华强 的居住地和工作地的名称,用英文冒号(:)拼接后提交。如居住地为华侨小区A区,工作地为新东方创业园,则提交的答案为:华侨小区A区:新东方创业园
根据一开始的检索信息,工作地名称是闵行区星辰信息技术园16楼✅,还差一个居住地名称。
写一个查询的脚本,检索某滴泄露的行程数据文件夹中的db数据,关键字设置为张**和138****9377
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
|
# -*- coding: utf-8 -*-
# @Author : 1cePeak
import sqlite3
import os
import argparse
def search_databases(keyword, target_field=None):
# 遍历当前目录下的所有.db文件
for filename in os.listdir('.'):
if not filename.endswith('.db'):
continue
print(f"\n正在搜索文件: {filename}")
try:
# 连接数据库
conn = sqlite3.connect(filename)
cursor = conn.cursor()
# 获取所有表名
cursor.execute("SELECT name FROM sqlite_master WHERE type='table';")
tables = cursor.fetchall()
for table in tables:
table_name = table[0]
print(f" 正在检查表: {table_name}")
# 获取表结构信息
cursor.execute(f"PRAGMA table_info({table_name})")
columns = cursor.fetchall()
column_names = [col[1] for col in columns]
# 处理目标字段
if target_field and target_field not in column_names:
print(f" 警告:字段 '{target_field}' 不存在,跳过该表")
continue
# 确定要搜索的字段列表
search_columns = [target_field] if target_field else column_names
# 获取所有数据
cursor.execute(f"SELECT * FROM {table_name}")
rows = cursor.fetchall()
# 遍历每一行数据
for row_idx, row in enumerate(rows):
# 遍历每个字段
for col_idx, col_name in enumerate(column_names):
if col_name not in search_columns:
continue
cell_value = str(row[col_idx]) # 转换为字符串进行匹配
# 检查是否包含关键字
if keyword in cell_value:
print(f" {filename}文件发现匹配!\n行号: {row_idx+1}")
print(f" 字段: {col_name}")
print(f" 命中内容: {cell_value[:100]}")
print(f" 所在行内容: {row}")
conn.close()
except Exception as e:
print(f"处理文件 {filename} 时出错: {str(e)}")
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="数据库文件内容搜索工具")
parser.add_argument("keyword", help="需要搜索的关键字")
parser.add_argument("-f", "--field", help="指定要搜索的字段(可选)")
args = parser.parse_args()
print(f"开始搜索:关键字 '{args.keyword}'", end="")
if args.field:
print(f" [仅限字段: {args.field}]")
else:
print(" [所有字段]")
search_databases(args.keyword, args.field)
|
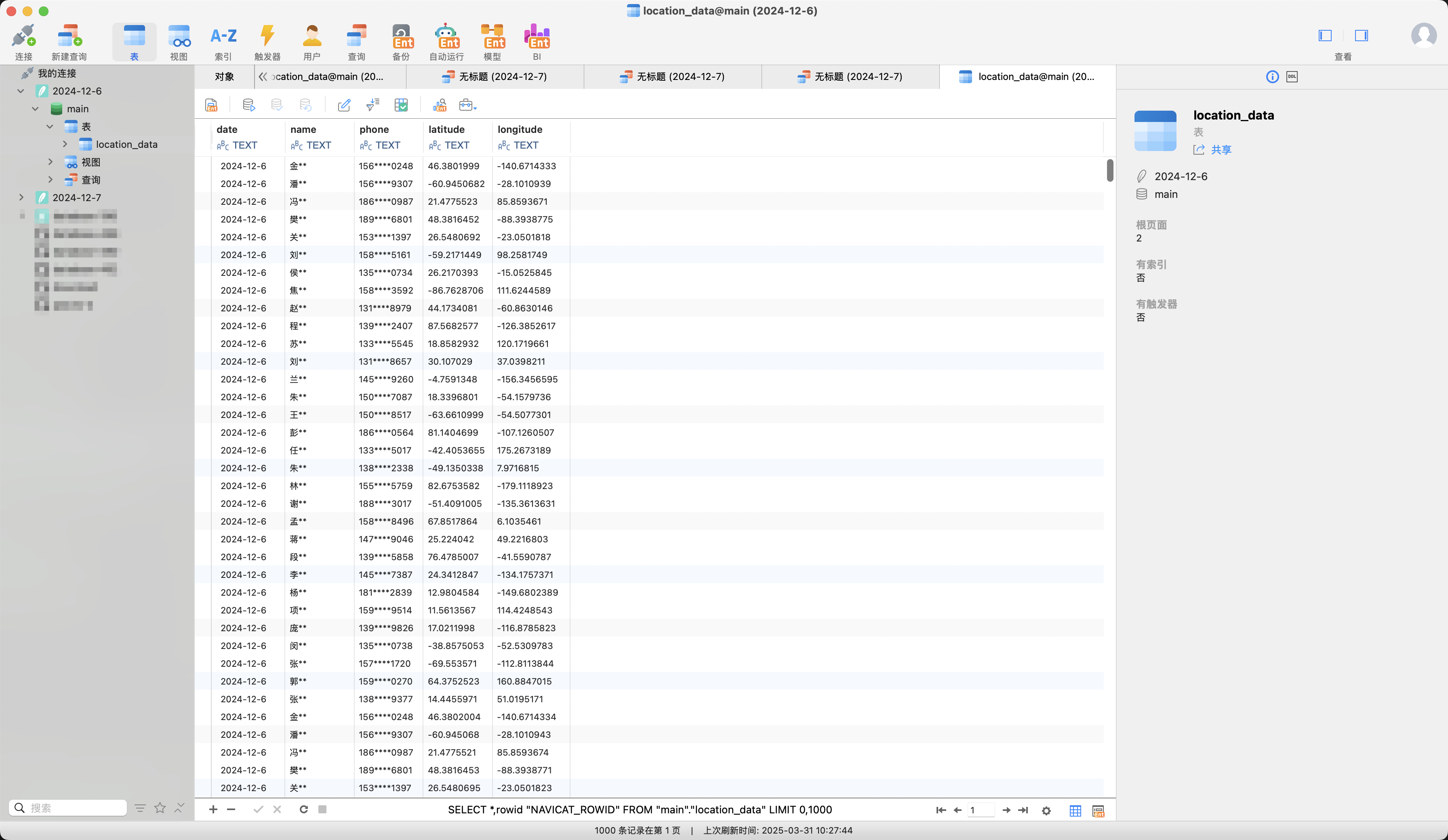
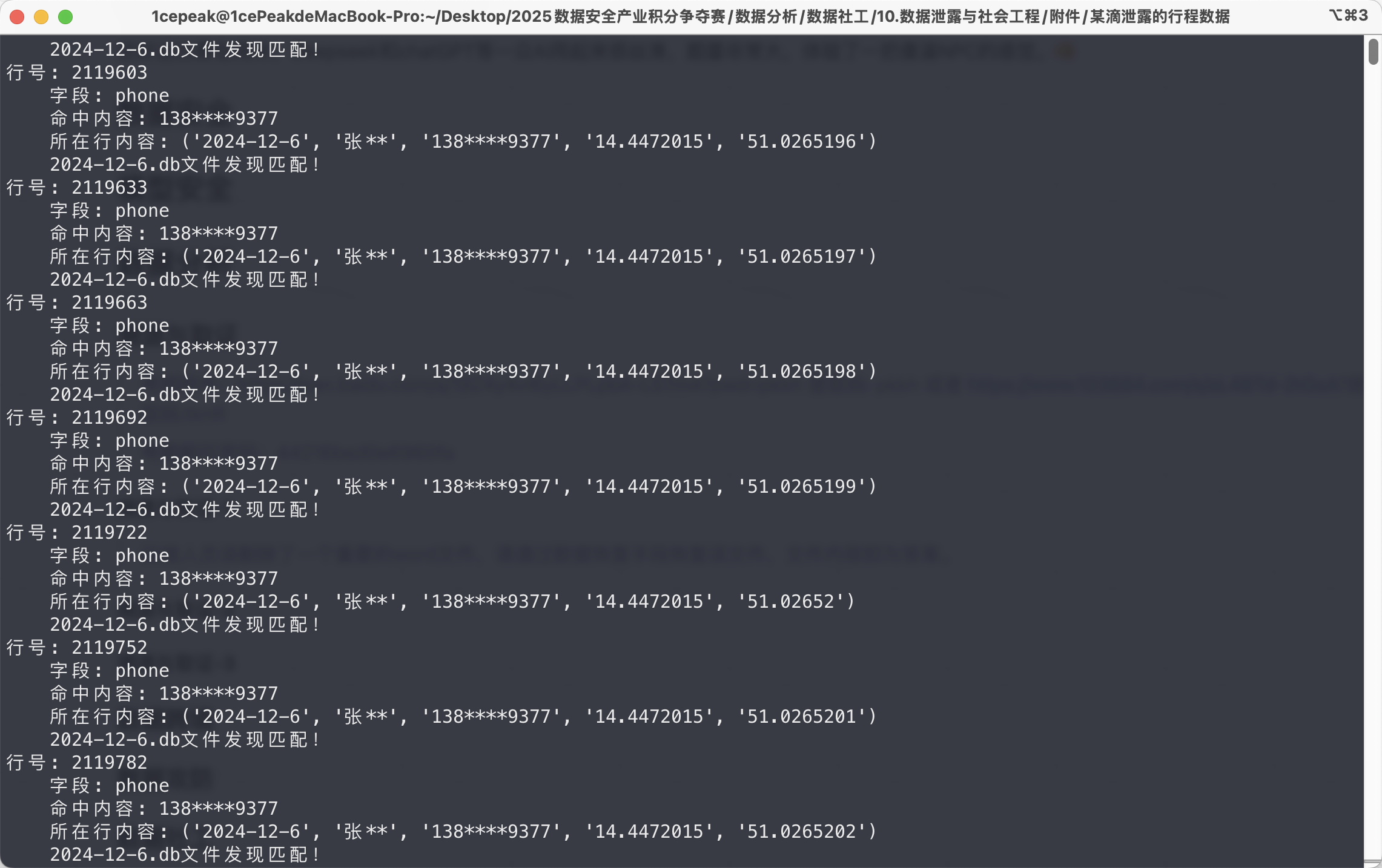
发现定位集中在(14.4472015, 51.0265198),接下来在某德泄露的地图数据文件夹中查询相应的地点名称。
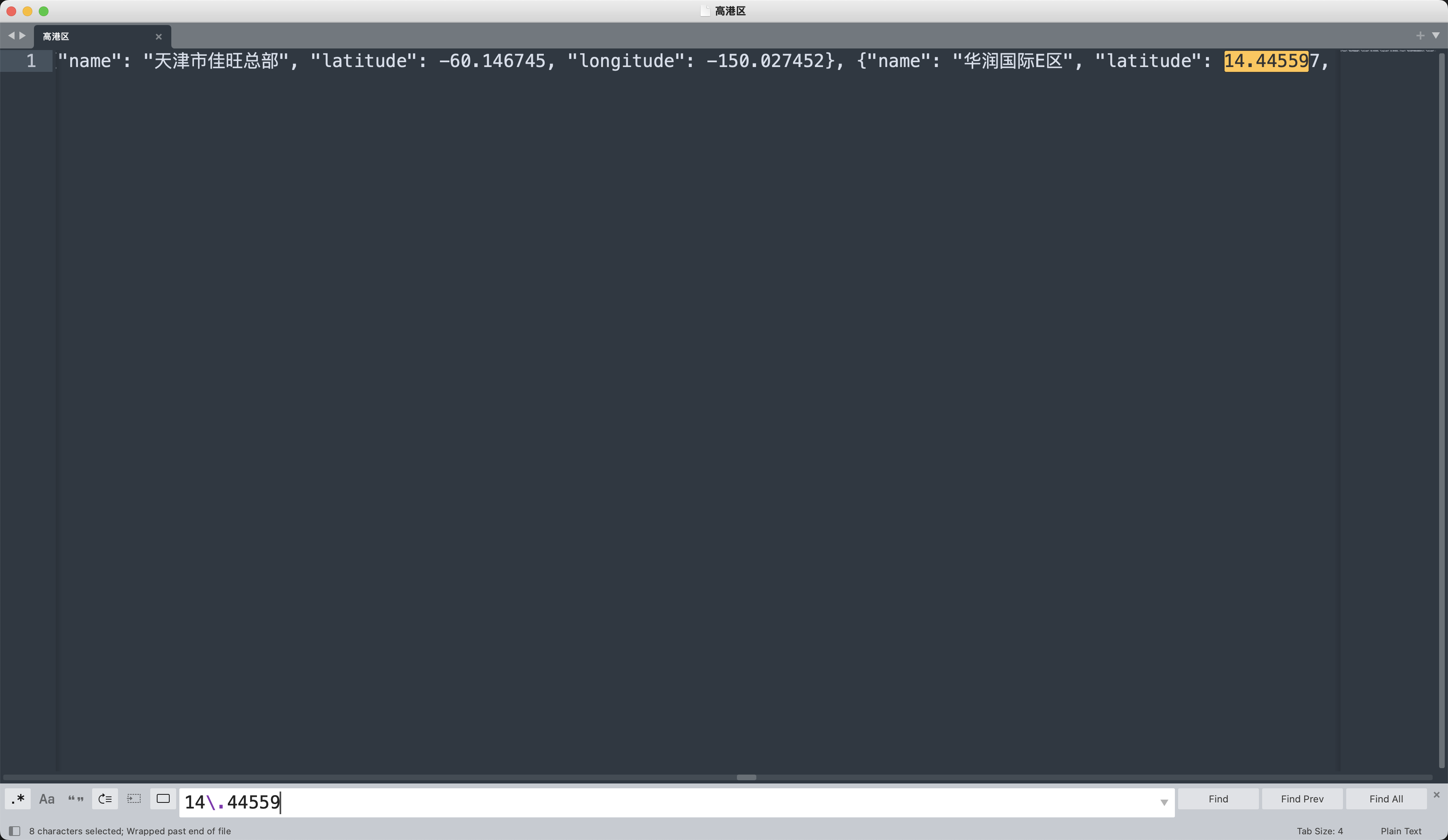
所以居住地名称是华润国际E区✅
数据社工-2-张华强的公司名称
重要
- 张某喜欢在公司收快递,地址一般为工作地+公司的简写,如
某某软件园凤凰传媒
- 参考爬取的企业工商信息,查询公司的正式名称
答案提交
提示
结合爬取的工商信息,提交张某所属公司的全称,如中国新东方有限公司
根据一开始的检索信息,公司名称是江苏博林科技有限公司✅
数据社工-3-张华强的手机号
重要
- 张某为企业的对外联络人
- 假设张华强仅有一个手机号,手机号为11位的明文数字
答案提交
提示
若确认张华强的手机号为18812345678,则提交18812345678,无其他字符
根据一开始的检索信息,手机号是13891889377✅
数据社工-4-张华强的身份证号
答案提交
提示
若确认张华强的手机号为31123119991010998X,则提交31123119991010998X,无其他字符
根据检索出来的张华强手机号13891889377,再来一次全局检索。
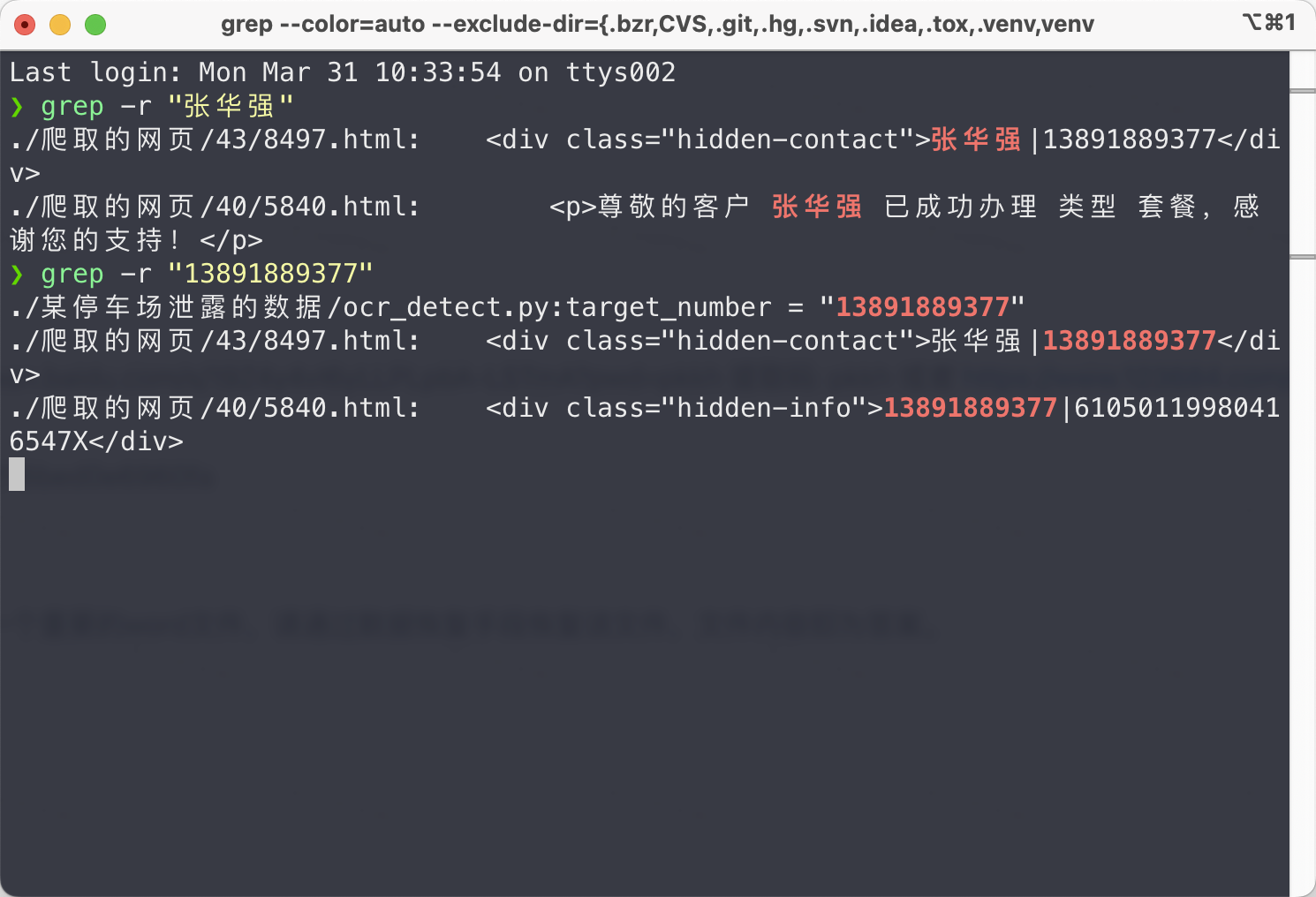
找到张华强的身份证号是61050119980416547X✅
数据社工-5-张华强的车牌号
重要
- 车牌号的格式为:
省的简写+大写字母+空格+5位字符,如苏D PT666,苏D和PT666中间存在一个空格
答案提交
若确认车牌为苏D PT666,苏D和PT666中间存在一个空格,则提交苏D PT666
思路就是通过手机号来检索停车场的出入记录,写一个OCR识别的代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
# -*- coding: utf-8 -*-
# @Author : 1cePeak
import os
import pytesseract
from PIL import Image
# 设置当前目录
current_dir = os.getcwd()
# 目标手机号
target_number = "13891889377"
# 获取当前目录下所有 jpg 文件
jpg_files = [f for f in os.listdir(current_dir) if f.lower().endswith(".jpg")]
# 存储包含目标手机号的文件名
matched_files = []
for jpg in jpg_files:
try:
print(f"[*] 正在识别 {jpg} 文件")
# 打开图片
img = Image.open(jpg)
# 使用 OCR 提取文本
text = pytesseract.image_to_string(img)
# print(text)
# 检查是否包含目标手机号
if target_number in text:
matched_files.append(jpg)
except Exception as e:
print(f"处理 {jpg} 时出错: {e}")
# 输出结果
if matched_files:
print(f"[+] 含有关键字 {target_number} 的文件:")
for file in matched_files:
print(file)
else:
print("[-] 未找到包含目标手机号的文件")
|
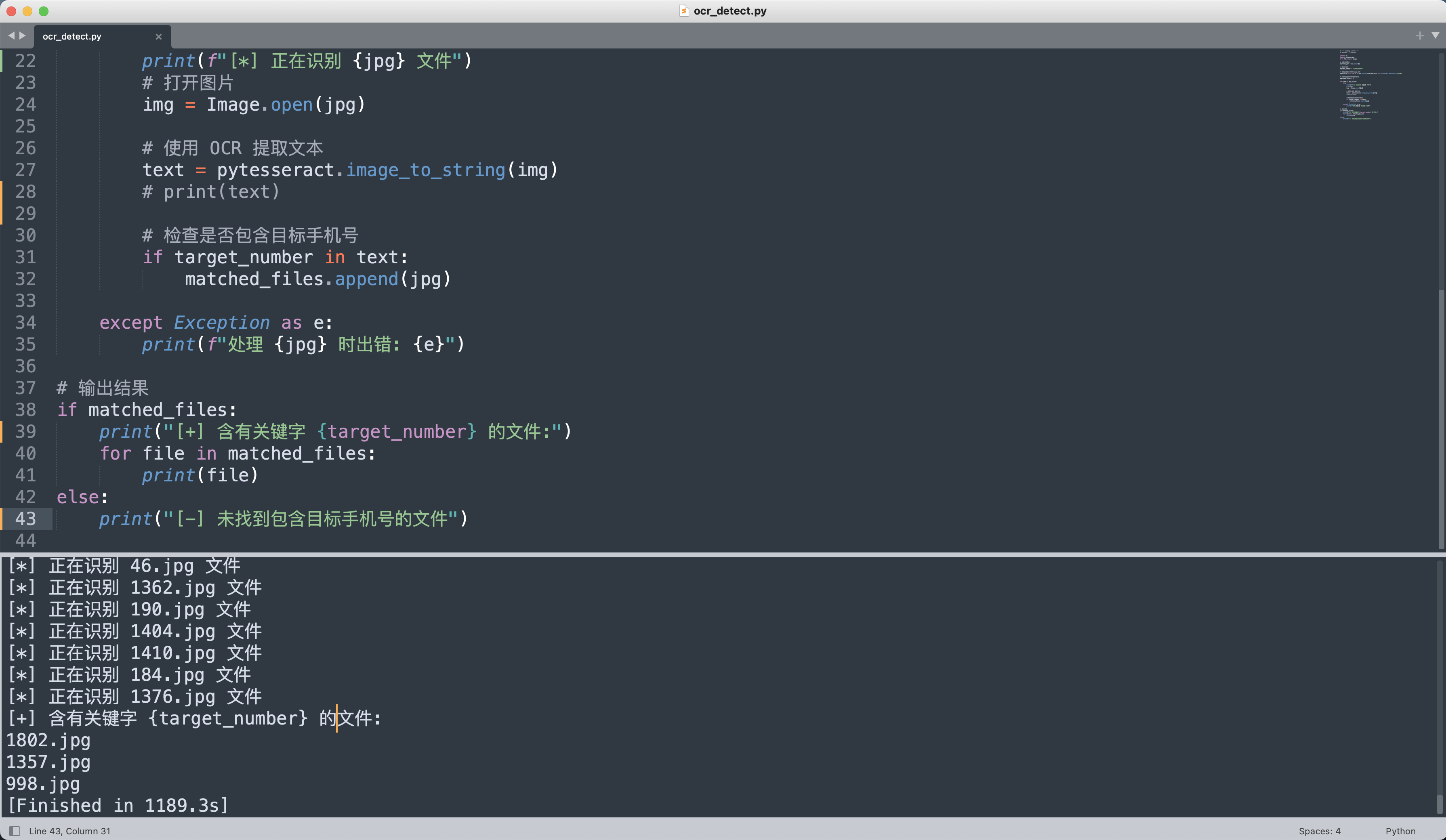
一共找到三条记录,均为13891889377登记的信息,车牌号是浙B QY318✅


