2026数字中国创新大赛数字安全赛道|网络和数据安全积分争夺赛Writeup
哥,再给我点token吧,我快不行了,求你了哥,我感觉我身上有蚂蚁在爬,我感觉我浑身都在抖,快不能呼吸了,求求你了哥,就再给我一点token吧,就一点就行,我再也不碰了,求求你了哥,我发誓我以后再也不碰这东西了!

个人赛
办公安全事件
办公安全事件第二问:
企业在向内部员工下发保密资产图片时,会预先在图片中嵌入该员工专属的不可见水印,以便日后追溯泄露来源。近期,安全团队在外网监测中发现一张与公司内部资料高度吻合的图片,判断其已被人私自外传,需从图片中提取水印,找出泄露者。
提交从图片中提取出的泄露者员工工号。
例:提取出的工号为 EMP-001,则提交答案为:EMP-001
先说结论:这题古法和AI都输了😭该试的都试了,A老师和G老师看了直摇头😴
本题的不可见水印采用了加法正弦水印(Additive Sinusoidal Watermarking)算法,将数据嵌入在频域(2D-FFT 幅度谱)中。
从这些图里可以明显观察到图片背景上存在规律性的斜向细条纹,翻一下每个RGB三个通道的样式,很明显水印主要嵌在蓝通道。
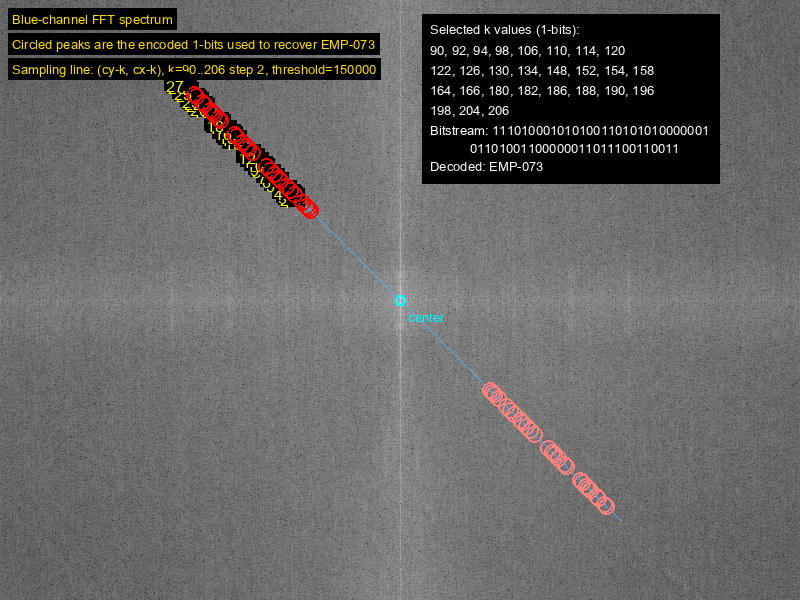
接着从蓝色频谱图里面找,沿着蓝通道频谱中心往左上角那条对角线去扫,提取一系列形如 (cy-k, cx-k) 的点的幅值,扫描一段范围后发现,在 k = 90 ~ 206、步长为 2 的这些点上,峰值分布非常有规律:
- 一部分点幅值非常高,大约在 16 万到 22 万之间;
- 另一部分点幅值明显低很多,通常只有几千到几万。
可以很快想到转换成0、1
- 有峰 =
1 - 无峰 =
0
于是设一个比较保守的阈值,比如 150000,把这些频点离散成 bit,得到:
|
|
可以得到01字符串
|
|
拿到 bit 串后,第一反应肯定是按 8 位切分转 ASCII。但这一步不会直接出结果,因为真实嵌入时很可能并不是从 bit 串的第 0 位刚好对齐,于是继续尝试不同偏移量。
删掉前面的三个1,从第 4 位开始,每 8 位分组时,刚好得到:
|
|
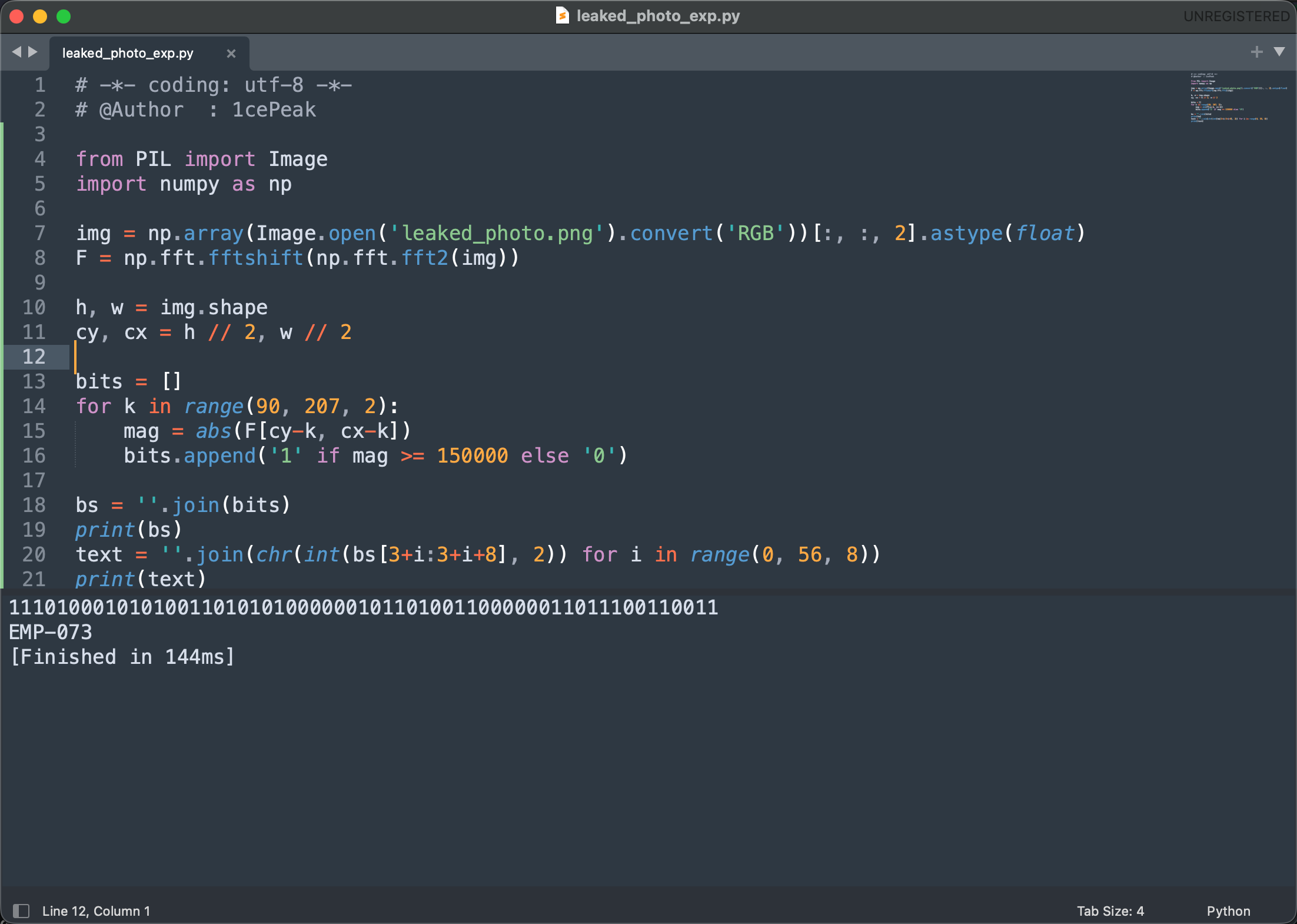
所以,这道题就是要把水印数据流按照合理的方式提取出来,代码核心逻辑虽然不长,但不是很好想到
总结一下:
- 读蓝通道;
- 做 FFT 并中心化;
- 沿频谱对角线取样;
- 用阈值判 0/1;
- 取正确偏移按字节解码。
最终答案是EMP-073
数据隐藏
题目描述:某科技有限公司为提升员工数据安全意识,编制了《2024年员工安全培训手册》,并通过内部办公系统下发至全体员工。近期,公司安全部门监测到,有恶意人员试图通过培训手册中的图片,隐蔽传输公司内部敏感数据(涉及内部系统访问密钥),规避公司安全监测。经排查,该敏感数据隐写在手册中某一张适合隐写的图片内,采用“字节最后一位嵌入”的隐写方式,且隐藏内容长度≤100字符。请分析《2024年员工安全培训手册》中的内容,找到被隐写的敏感数据,将提取出的完整密钥进行提交(例如:uq_live_8Xm2pL9qR4tK7jH3fN6dG5wV)
先检查一下题目给的附件,是一个含有docx文件的压缩包。
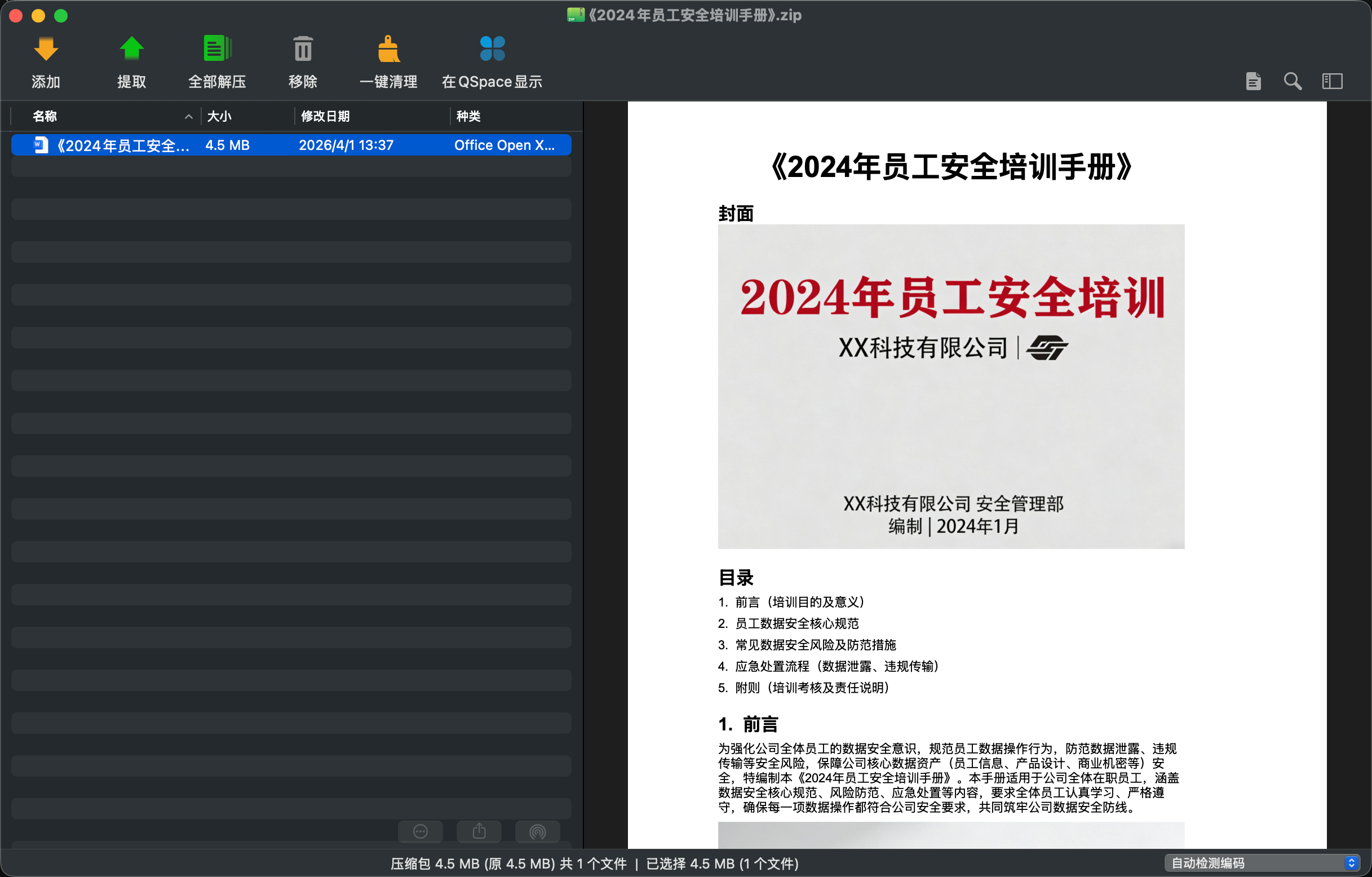
文档中可以提取出5张图片,其中image1.png ~ image4.png 的时间戳都比较旧,只有image5.png的时间戳非常新,是2026-04-01 13:31,常规的LSB和各种妙妙小工具都投降了🙌,当然也有可能是哪个0 watch 0 fork 0 star的仓库横空出世了。
根据题目描述“采用字节最后一位嵌入的隐写方式”,感觉是自定义的LSB隐写方法,这类方式常见的做法就是:
- 先选定一条字节序列(例如某个颜色通道)
- 再设置一个固定步长
step - 从某个起始偏移
start开始 - 每隔
step个字节取一次最低位
也就是:
|
|
取满 8 × 消息长度 个 bit 后,再按每 8 bit 拼回一个字符。
这就和普通 LSB 最大的区别在于:
- 普通 LSB:
step = 1 - 本题:
step是一个需要被恢复出来的参数
因为题目已经明确说“隐藏内容长度 ≤ 100”,所以搜索空间其实没有看起来那么夸张。再结合“密钥通常是可打印 ASCII 字符串”这一点,我们可以用下面的标准筛候选结果:
- 输出是否是高比例可打印字符
- 是否像一个系统密钥/访问令牌
- 是否包含字母、数字、下划线等典型密钥字符
经过参数搜索后,最后在 image5.png 的 G 通道 上命中了完全可读的结果,正确参数为:
- 通道:
G - 消息长度:
32 - 步长:
3217 - 起始偏移:
5 - 组字节方式:MSB(高位在前)
对应的提取代码如下:
|
|
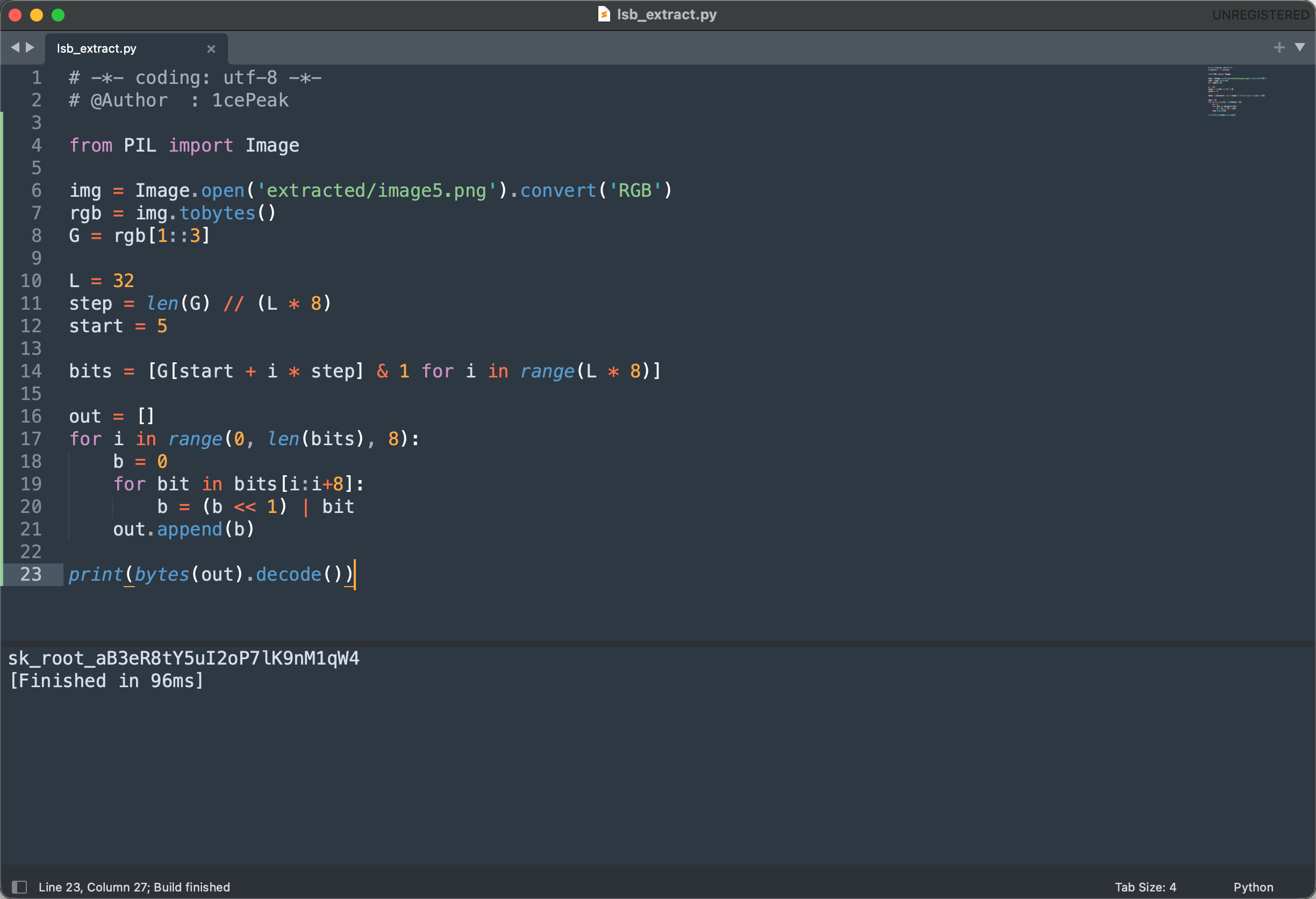
最终答案是sk_root_aB3eR8tY5uI2oP7lK9nM1qW4